+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
In today’s fast-paced landscape of data engineering and analytics, maintaining high data quality is crucial. As organizations increasingly depend on data-driven insights for strategic decision-making, the tools and methodologies employed to uphold data integrity become vital to their success. Among these tools, the data build tool (dbt) has emerged as a powerful ally, enabling teams to transform and manage their data.
This article aims to demonstrate why dbt should serve as a cost-effective solution for enhancing data quality across your organization. By implementing dbt, data quality assurance teams can establish a robust routine for testing data during critical phases, such as data reloads, new data introduction, and transitions between environments. dbt offers a suite of tests that simplify the validation process, ensuring that your data adheres to essential criteria and standards before it is utilized for analytics or business intelligence.
By leveraging these capabilities, data teams can significantly streamline their workflows, reducing the time and effort required to maintain high-quality data. In the sections that follow, we will explain why you should use dbt by proving how easy it is to use. Whether you are an experienced data engineer or just starting your journey, understanding how to utilize dbt tests effectively will empower you to enhance the quality of your data transformation processes, ultimately leading to more accurate and reliable data outcomes.
Types of tests
Let’s start with the types of tests that dbt offers. Tests in dbt can be divided into three categories:

Generic tests
Generic tests in dbt are predefined tests that can be applied to multiple models, columns, or tables within a data project to validate data quality and integrity. They are designed to test if the data being transformed and loaded meets certain predefined criteria. Generic tests should be inserted into a `model.yml` file, which should be located alongside your SQL model in your dbt project directory. The `model.yml` file should have the same name as the SQL model file (depending on the approach, tests for all models could be located in one 'schema.yml’ file as well. In this article, we will cover the model-specific approach.)
There are four generic tests that dbt contains by default:
- unique: checks if the values in the column are unique
- not_null: checks for any nulls in the column
- accepted_values: checks if a specific list of values is present in the column. Additional conditions can be added to analyze if, with the specific set of values in the other columns, there is a correct value present.
- relationships: checks if every row in the transaction table has a corresponding record in the given table
You can expand the list of generic tests by using the dbt-utils library or by creating your own tests.
Generic-custom tests
When the basic package of generic tests is not enough, users can conduct their own generic tests and add them to the project. You can define your own reusable generic tests in the form of macros and use them in the `model.yml` file like the generic tests provided by dbt. Like in the case of custom tests, these tests should be created in the SQL file format. These files should be placed in the `macros` folder in the dbt project directory.
Custom tests
For some specific use cases (e.g., logic that will not be reused in other models), using a generic test is not enough, and custom generic tests are not necessary. In this case, users can create their own test that will be applied to the specific model. These tests should be located in the `tests` folder in your dbt project directory. The accepted format is a SQL file. From the perspective of dbt, the name of the custom test does not matter. It should be created to inform the user of its contents. Custom tests will fail by default if the result is different from 0 (`!= 0`). It can be configured to pass or fail with other conditions (e.g., greater than 0, equal to a number, equal to another column). dbt will understand that this test is related to the specific model because of the `{{ ref(’model’) }}`.
Why should you use dbt tests as QA?
Having covered the different test types in the previous section, let’s now consider why you should use them as a QA professional. We’ll assume that dbt is already implemented in your project and is being used for data operations. We’ll focus specifically on the testing part.
To learn how to configure dbt on your side, please refer to the dbt documentation. What is important is to be sure that you will create a virtual machine with a Python version that is the same as the one that is used in the project. The same case is with the dbt version; versions should match.
Creating tests in dbt is low cost and high reward
Implementing tests in dbt is very easy and fast. Instead of writing a script or query that will check if the data is correct, you can create a test in dbt. For example, when you get to test a new model, you can create tests to check basic data quality criteria in no time. Let’s look at the example below.
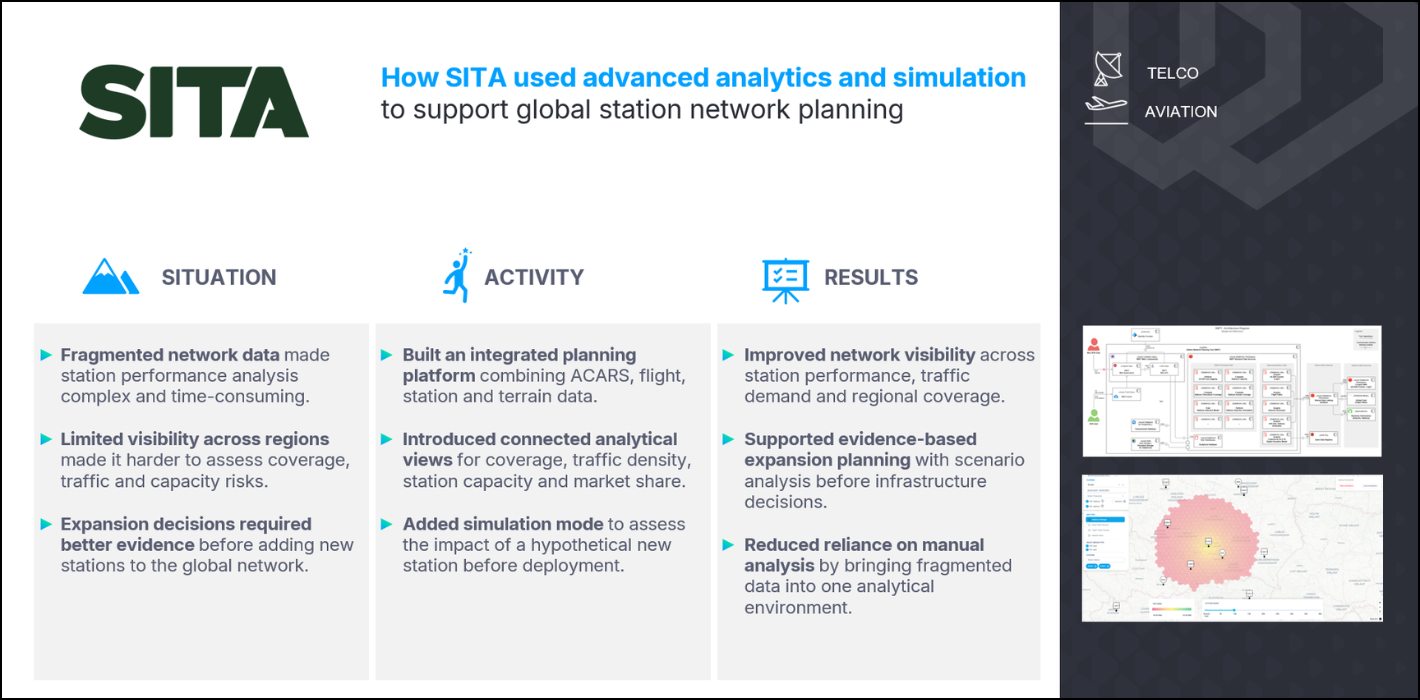
In the project directory, we have a model named `clients.sql`:
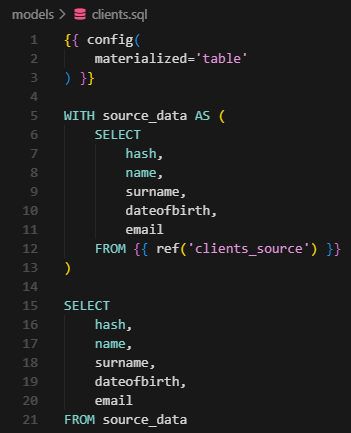
This file should have its `.yml` equivalent file named `clients.yml`. If there is no such file, you can create it manually. The structure should look like this:
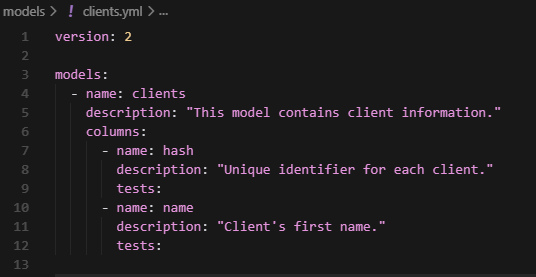
In this case, the user knows that `hash` should be unique. Let’s add a test that will check it.
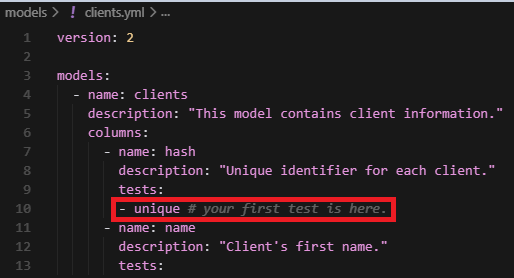
Congratulations! You have just created your first test in dbt. Now you can run it by running the command:
“dbt test -s clients”
Another option is to run the command:
“dbt test”
This will run all the tests in the project. In the case of repositories containing multiple models, it is recommended to run tests for specific models or related to a specified exposure (exposure is a dbt name for models related to the user-specified tag). For more information about exposures, please refer to the dbt documentation.
This is an example of running dbt test command
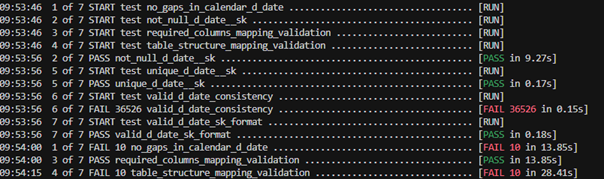
![]()
Automated testing
Even if you are new to dbt or automated testing, dbt testing offers a very low barrier of entry. After you implement a dbt test as described above, you receive a half-automated testing procedure (you still have to run testing by yourself at this point). But you don’t have to search for queries that you wrote before, and you don’t have to run them one by one. You just run the command and get the results. Of course, you can fully automate the process by including tests in CI/CD pipelines.
Guarding data trails by including tests in CI/CD pipelines
Implementing dbt tests within CI/CD pipelines is a crucial step towards achieving fully automated data quality assurance. By integrating dbt tests into your CI/CD workflows, you ensure that data quality checks are consistently applied every time a change is made to your data models. This integration helps in catching data quality issues early in the development process, reducing the risk of deploying faulty data to production environments. Now you will be sure that data will be checked and validated when new data is being loaded or when you are rolling to the next environment.
Better cooperation within the development team
Using dbt for quality assurance fosters better collaboration in the team. When a dbt project is managed in a version-controlled environment, the team can work from the same codebase, ensuring that everyone is aligned on the current state of the data models and tests. This shared understanding reduces miscommunication and helps both teams quickly identify and resolve issues.
Consistency and synchronization in testing
By integrating tests directly into the dbt project repository, QA can ensure that tests are always synchronized with the data models they are meant to validate. This minimizes the risk of desynchronization, where tests might become outdated or irrelevant due to changes in data models or business logic. With dbt, tests are version-controlled alongside the data models, which means any updates to the models can be accompanied by corresponding updates to the tests. This tight coupling between models and tests ensures that as the data evolves, the tests evolve with it, maintaining their relevance and accuracy.
Self-writing documentation
Who likes to write documentation? Even if someone does, dbt offers a way to do it better, faster, and always consistently. The ability to automatically generate documentation for your data models and tests is one of the standout features of the data build tool. This self-writing documentation functionality is a game-changer for teams looking to maintain comprehensive and up-to-date documentation without the manual overhead. When you define models and tests in dbt, you can include descriptions and metadata directly in your YAML files. dbt then uses this information to generate a rich, interactive documentation site that provides insights into your data models, their relationships, and the tests applied to them.
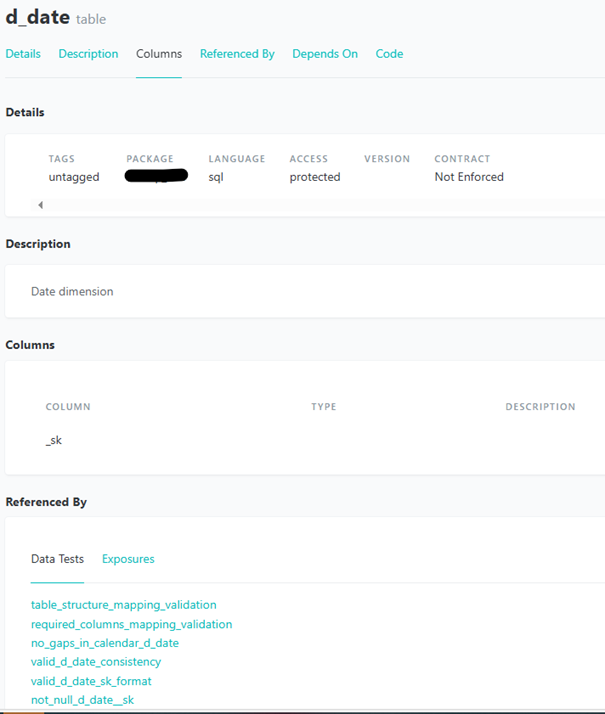

This documentation is automatically updated whenever changes are made to the models or tests, ensuring that it always reflects the current state of your project. As a result, you will have more time to focus on testing instead of spending it updating documentation after every change.
Scalability
Whether you are working on a small project with a few models or a large enterprise-level data warehouse with hundreds of models, dbt can handle it all. Its modular architecture allows teams to start small and gradually expand their dbt projects as their data needs grow. You could say that dbt will grow with your organization. From the perspective of a QA, it can guarantee that no matter how big your project is, you will be able to test it with ease.
Insights and from the perspective of a QA engineer
Not utilizing dbt in your QA processes, especially if it’s already adopted by your organization, is a missed opportunity. As mentioned earlier, the setup is straightforward, and the maintenance is minimal compared to the significant gains in data quality and reliability. The low cost of implementation relative to the high return on investment makes it an invaluable tool for any data team.
- When beginning your journey with dbt, it’s crucial to start with the built-in generic tests. These tests are designed to cover common data quality issues and provide a solid baseline. Be sure to use the dbt-utils package to expand the list of generic tests. Custom tests can be complex and may introduce unnecessary complications early on. By implementing the generic tests first, you can ensure that your data meets essential quality standards before venturing into more intricate custom solutions. Of course, there will be situations where you will need to create your own tests, but you should always use this testing rule: easier tests first, more complex tests later. This approach lets you save time and resources by testing a wider range of data with less effort.
- If you find a bug on this level, it can be fixed and not cause more complex tests to fail (this means less complex investigation and less time spent on fixing the issue).
- Implementing generic tests first is a quick win because you can test more data with less effort.
- Integrating dbt tests early in your project lifecycle is vital. By establishing a robust testing routine from the outset, you create a safety net that allows for more confident data manipulation throughout the development process. This proactive approach ensures that as your project evolves, you can trust the integrity of your data across all environments. Shift-left testing is another topic that is worth covering with dbt. It allows you to save resources even more effectively.
- When preparing your tests, focus on the most critical data elements first, especially those that are easiest to implement. This is the same case as when using generic tests first. For instance, if you know that a primary key in a table should be unique, start with the simple `unique` test. This not only addresses significant data quality concerns but also builds momentum for your testing efforts. Conversely, if a column has multiple conditions but is not crucial for immediate data quality, it can be deprioritized for later implementation. You should start with the most critical and easiest tests first.
- Data quality assurance is an ongoing process. As you gain insights from your initial tests, be prepared to iterate and refine your testing strategy. Regularly review your tests to ensure they remain relevant and effective as your data models and business requirements evolve.
- Collaborate with the stakeholders to understand their priorities and concerns regarding data quality. This engagement can help you identify which tests will have the most significant impact and ensure that your testing efforts align with business objectives. This point may seem trivial, but it can save you much work.
- The dbt documentation is a valuable resource, but don’t overlook the power of community engagement. Participate in forums, attend workshops, and share your experiences with peers. For example, Reddit is a great place to search for a solution. Learning from others can provide new perspectives and innovative approaches to data testing.
- Sometimes functionalities from an older version of dbt will not work in newer versions. From dbt 1.10, deprecation warnings are introduced for issues such as unrecognized resource properties, duplicate YAML keys, and unexpected Jinja blocks. While these warnings do not immediately break your project, they signal code that will become invalid in future dbt releases. It is strongly recommended to address all deprecation warnings as part of your QA process to ensure long-term compatibility and prevent future build failures.
- Auto-formatting in IDEs may normalize uppercase letters to lowercase in Jinja. It can lead to problems with model or test execution. For example, when column names have uppercase letters in them, dbt may not be able to use them after formatting the script.
- Sometimes, the investigation of a failed test can be a challenge. dbt does not offer good plain text error information. Outcome is based on the created condition (e.g., `unique` test is formatted to fail when `!= 0`). In both cases, the user will have to analyze what is the cause of the issue.
- It is important to correctly plan tests cost-wise. Every test is a query to a warehouse (e.g. Databricks SQL). Query is a cost. The test of a column’s uniqueness is a full scan on that column. Cost optimization is an integral part of the quality assurance process.
Summary
As you can see, not using dbt as QA would be a missed opportunity. dbt enhances the testing functionalities by offering a comprehensive suite of utilities that facilitate detailed and effective data quality checks. Whether through out-of-the-box generic tests, schema validations, or custom test definitions, dbt empowers data teams to enforce data integrity and reliability across their dbt projects with ease and precision. By implementing dbt testing, QA teams can establish robust routines for testing data during critical phases, ensuring that their data adheres to essential criteria before being used for analytics or business intelligence.
Useful links:
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.