(+48) 453 250 842
(+48) 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
Amazon Simple Storage Service (S3) is a cloud storage solution known for its scalability, reliability, and security. S3 storage can be used in many ways for many use cases. However, they all have one thing in common: cost management.
Managing costs on S3 may be demanding for companies that migrate their on-premises solutions to the AWS cloud or for those with non-standardized storage management policies. Improperly managing S3 costs can cause expenses to rapidly escalate and have a serious impact on budgets.
This article will give a concise overview of how to optimise costs on S3 by implementing appropriate standards. I will explore strategies such as selecting appropriate storage classes, leveraging lifecycle policies, and efficient data management to help you manage your S3 expenditures efficiently. We will focus on best practices for storing and processing data files. By understanding the nuances of data file management in S3, you will be better prepared to reduce costs.
Ways to optimise costs
Storage classes
Amazon Simple Storage Service (S3) offers multiple storage classes that are designed for different storage needs, optimizing costs and performance. Each storage class is intended for a different use case, providing flexibility in how data is stored and accessed. Understanding these storage classes is crucial for effective data management and cost optimization in the cloud.
- S3 Standard
Should be used for frequently accessed data. It offers high durability, availability, and low latency. - S3 Intelligent-Tiering
Automatically moves data between two access tiers based on changing access patterns. - S3 Standard-IA (Infrequent Access)
Should be used for infrequently accessed data. It offers lower storage costs with a retrieval fee. - S3 One Zone-IA
Similar to Standard-IA but stored in a single availability zone. It offers lower costs for infrequently accessed data with slightly less durability. - S3 Glacier Instant Retrieval
Designed for archival storage with immediate access to data. Data retrieval is instant. - S3 Glacier Flexible Retrieval
Designed for long-term archival with retrieval times ranging from minutes to hours, offering very low storage costs for data that is rarely accessed. - S3 Glacier Deep Archive
The lowest-cost storage option for data that is accessed very infrequently, with retrieval times ranging from 12 to 48 hours, is ideal for data that needs to be preserved for years or decades.
You can find detailed descriptions of Storage Classes in the documentation, links below:
Lifecycle Policies
Lifecycle policies are a set of rules that define the actions performed by Amazon S3 to a group of objects. These rules are used to move objects into different storage classes and archive or delete them after a certain time. Lifecycle rules are divided into “Transition actions” and “Expiration actions”. Actions are based on the creation date for the current file version. For noncurrent versions of objects, you define the number of days after which action should be performed.
Transition actions
Transition actions are responsible for moving objects to another storage class based on their age or the date they were created. Example of transition actions:
- Move objects from S3 Standard to S3 Standard-IA 30 days after creation
- Move objects from S3 Standard to S3 One Zone-IA 60 days after creation
- Move objects from S3 Standard-IA to S3 Glacier 90 days after creation
- Move objects from S3 Glacier Flexible Retrieval to S3 Glacier Deep Archive 180 days after creation
Expiration actions
Expiration actions are responsible for permanently deleting objects, thus freeing up storage space and reducing costs. Example of expiration actions:
- Delete objects 100 days after creation
- Permanently delete previous versions of objects older than 15 days
- Delete objects based on a prefix older than 15 days
- Delete objects based on a tag older than 15 days
Efficient Data Management
Aggregation of small files
Small files can cause inefficiencies and higher costs in Amazon S3 due to the overhead associated with storing and retrieving each individual object. Aggregating small files into larger objects can significantly reduce these costs and improve performance.
- Reduced Storage Overhead: Amazon S3 charges based on the number of objects stored and the storage used. By combining small files into larger objects, you reduce the number of objects, thereby lowering overhead costs
- Lower Request Costs: Each PUT, GET, and LIST request incurs a cost. Aggregating files reduces the number of requests needed to manage and access your data
- Improved Performance: Fewer objects mean fewer metadata operations, which can lead to faster access times and more efficient data retrieval
- Potential reduced requests number:
- To other services: e.g. when you use KMS you will reduce encrypt and decrypt requests
- Data transfer
- S3 Replication
Data compression
Data compression is another effective strategy for reducing storage costs and improving data transfer efficiency. Compressing data before storing it in Amazon S3 reduces the amount of storage space required and can lower data transfer costs. Currently, Amazon S3 does not offer native data compression features, so compression must be handled by the data provider or user before/after files are uploaded to S3.
- Reduced Storage Costs: Compressed data occupies less space, which directly translates to lower storage costs
- Faster Data Transfers: Compressed files are smaller, resulting in faster uploads and downloads, and reduced data transfer costs
- Improved Performance: Smaller file sizes mean quicker retrieval times, enhancing the overall performance of data access
Example of data compression:
When you work with CSV files, it is beneficial to store them in a compressed .gz format. PySpark can decompress these files when loading data, allowing compressed CSV files to be read directly.
df = spark.read.format(„csv”).option(„header”, „true”).load(„datafile.csv.gz”)
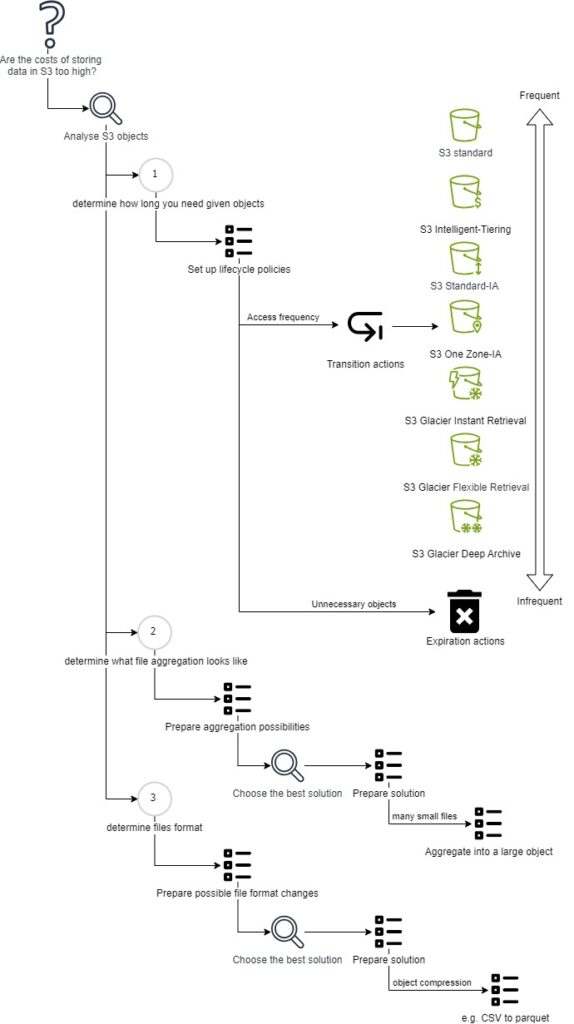
Algorithm of decreasing S3 costs
The diagram below shows how to approach effective cost management on S3 from a data storage perspective.
Use cases
Introduction
The presented cases are among the most common. They show typical storage management problems, possible solutions, and real benefits resulting from properly applied cost management practices.
Case #1
Brief introduction
A company needs to reduce costs, and they look for some solutions. They use many AWS services, and they have conducted an audit. It turned out that S3 is one of the most expensive services. The company asked for a cost-effective S3 storage management policy.
As-is state:
- All S3 objects are stored in S3 standard storage class
- No lifecycle policies are set
- Company receives 3k files per month
- Expected average new file size for the next 12 months: ~1 GB
- There is one bucket to optimize
- Raw bucket – where source files are stored
- Files are accessed for 30 days and then only once or twice a year, if at all
- Files should be available immediately when needed
- Data cannot be deleted
- CSV file format
- Region: us-east-1
- 600k objects
- Total size: 60 TB
- Storage cost: $1370 per month
- Raw bucket – where source files are stored
- Files are not divided into many small parts
Possibilities to reduce costs
In this scenario, the best storage classes to use are S3 Standard and S3 Glacier Instant Retrieval. S3 Standard will handle files accessed for 30 days, and after that time, they should be transferred to S3 Glacier Instant Retrieval. Changing the file format from CSV to Parquet will reduce the total files size by 2 to 10 times. This solution provides high durability, availability, low latency, and is more cost-efficient.
To achieve this, there are two possible steps to reduce costs:
- Create a lifecycle rule to move objects to Glacier Instant Retrieval Storage class 30 days after object creation
- Change file format to Parquet – prepare job to convert CSV files to Parquet Costs were calculated in June 2024.
Current pricing: S3 pricing documentation.
| Solution | Objects number | Total size | Storage class | Cost per month |
| As-is | 600k | 60TB | S3 Standard | 1 370,00 USD |
| CSV to Parquet | 600k | 6TB-30TB | S3 Standard | 138,00 – 690,00 USD |
| Glacier Instant Retrieval | 600k | 57TB + 3TB | Glacier Instant Retrieval + S3 Standard | 297,00 USD |
| Parquet + Glacier Instant Retrieval | 600k | 5,7TB-28,5TB + 3TB | Glacier Instant Retrieval + S3 Standard | 91,80 – 183,00 USD |
We can see the difference between different variants in the cost-per-month perspective. The file format transformation significantly reduces cost even when using S3 Standard storage class, as does moving unused objects to Glacier Instant Retrieval. The combination of these two scenarios gives the best result.
Let’s compare costs from a 12-month perspective, including transition costs and data delivery.
| Month | Objects number | CSV total size | Parquet total size | As-is solution | Parquet + Glacier Instant Retrieval | Transition costs | |
| Lowest | Highest | ||||||
| 1 | 600 000 | 60TB | 6TB-30TB | 1 370,00 USD | 91,80 USD | 183,00 USD | 5,97 USD |
| 2 | 603 000 | 63TB | 6,3TB-31,5TB | 1 436,00 USD | 93,00 USD | 189,00 USD | 0,03 USD |
| 3 | 606 000 | 66TB | 6,6TB-33TB | 1 502,00 USD | 94,20 USD | 195,00 USD | 0,03 USD |
| 4 | 609 000 | 69TB | 6,9TB-34,5TB | 1 568,00 USD | 95,40 USD | 201,00 USD | 0,03 USD |
| 5 | 612 000 | 72TB | 7,2TB-36TB | 1 634,00 USD | 96,60 USD | 207,00 USD | 0,03 USD |
| 6 | 615 000 | 75TB | 7,5TB-37,5TB | 1 700,00 USD | 97,80 USD | 213,00 USD | 0,03 USD |
| 7 | 618 000 | 78TB | 7,8TB-39TB | 1 766,00 USD | 99,00 USD | 219,00 USD | 0,03 USD |
| 8 | 621 000 | 81TB | 8,1TB-40,5TB | 1 832,00 USD | 100,20 USD | 225,00 USD | 0,03 USD |
| 9 | 624 000 | 84TB | 8,4TB-42TB | 1 898,00 USD | 101,40 USD | 231,00 USD | 0,03 USD |
| 10 | 627 000 | 87TB | 8,7TB-43,5TB | 1 964,00 USD | 102,60 USD | 237,00 USD | 0,03 USD |
| 11 | 630 000 | 90TB | 9TB-45TB | 2 030,00 USD | 103,80 USD | 243,00 USD | 0,03 USD |
| 12 | 633 000 | 93TB | 9,3TB-46,5TB | 2 096,00 USD | 105,00 USD | 249,00 USD | 0,03 USD |
| SUM | 20 796,00 USD | 1 180,80 USD | 2 592,00 USD | 6,30 USD | |||
Summary
We can see that the predicted costs for the 12 months result in a huge difference. The company can save ~18k/19k USD in 12 months in comparison to the current solution.
Case #2
Brief introduction
A company is looking for some cost improvements of S3 service. They requested an audit.
As-is state:
- All S3 objects are stored in appropriate storage classes
- Lifecycle policies are set:
- Transaction actions – move objects to the appropriate storage class
- Expiration actions – remove objects at the appropriate time
- The company receives ~5k files per month
- On average, they receive one file in ~20 parts (250 files)
- Average file (part) size: ~5 MB
- On average, they receive one file in ~20 parts (250 files)
- The company uses one bucket
- Parquet file format
- Region: us-east-1
- There is no aggregation job – there is a possibility of doing it
Possibilities to reduce costs
In this scenario the lifecycle policies are correctly used – there is no need for improvement. There is no possibility to change the file format. It is possible to aggregate data by combining many small files into one. This will reduce the number of requests and will be a more cost-effective solution.
To achieve this, there are two possible options to reduce costs:
- Create a job to combine files
- Instruct data providers to send data in one file
Creating the job to combine files is not the best solution from a cost-effective perspective, but sometimes, this is the only way. You have to prepare and maintain the new solution. This is reflected in the increase in operational costs, and this solution does not reduce costs as much as the second approach. A better solution is to outsource this directly to data providers, but their cooperation and flexibility are required. The comparison of these two approaches is presented below:
| Aspect | Aggregate files in AWS | Instruct Data Providers to send a single file |
| Implementation Complexity | Moderate | Low |
| Cost | Medium | Low |
| Maintenance | High | Low |
| Operational Overhead | High | Low |
| Time to Implement | Moderate to High | Low to Moderate (could be longer) |
| Integration Complexity | High | Low |
| Cost Predictability | Moderate | High |
| Provider Cooperation | Not Required | Essential |
Summary
Our recommendation is to instruct data providers to send the data in a single file. This solution results in lower costs and effort but cooperation with data providers is crucial.
Case #3
Brief introduction
A company is looking for some cost improvements of S3 service. They requested an audit.
As-is state:
- All S3 objects are stored in appropriate storage classes
- Life cycle rules are set up properly
- The company uses one bucket
- Region: us-east-1
- Parquet file format
- ~28 million objects
- Total size: ~3 TB
- Storage cost: ~ $80 per month
- API requests number: ~1 000 000 000 000
- Cost: ~ $600 per month
- Requests number to KMS: ~230 000 000
- Cost: ~ $700 per month
- Requests number to GuardDuty: ~1 000 000 000 000
- Cost: ~ $500 per month
- The company has too many small files: files ~100 KB per object
Possibilities to reduce costs
Implementing Delta Lake can help reduce the costs associated with excessive API requests and inefficient storage usage caused by too many small files. Delta Lake uses compaction techniques that combine smaller files into larger ones. To realize these savings, you need to integrate Delta Lake into your existing environment.
| Cost Category | Before Delta Lake | After Delta Lake | Savings |
| S3 Storage | 80,00 USD | ~ 80,00 USD | 0,00 USD |
| S3 API Requests | 600,00 USD | 240,00 USD | 360,00 USD |
| KMS Requests | 700,00 USD | 280,00 USD | 420,00 USD |
| GuardDuty Requests | 500,00 USD | 200,00 USD | 300,00 USD |
| Total Monthly Cost | 1 880,00 USD | 800,00 USD | 1 080,00 USD |
It is worth mentioning that the processing itself is also 5 times faster than before (previously it took around 12 hours).
Summary
Implementing the Delta Lake solution has resulted in savings of $1 000 per month.
Summary
Cost-effective S3 management can be easily implemented through the implementation of a few simple rules or the use of S3 Intelligent-Tiering or very complex ones containing dedicated rules relating to specific locations. Proper S3 management is very important for companies dealing with Big Data as the size of the data reaches unimaginable proportions. Failure to manage S3 or doing it in the wrong way can have a serious impact on budgets.
Each case is different, even if very similar. The key factors are constraints, client and environment requirements, and finally cooperation during the analysis. Openness and cooperation are key to a reliable analysis, which has a huge impact on further actions.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.