
 (+48) 508 425 378
(+48) 508 425 378 office@bitpeak.pl
office@bitpeak.pl


The client
Santander Bank Polska, one of the biggest Polish banks with 10,000 employees and a part of a global group with 166 million customers, € 1,020 bn customer loans, € 1,800 bn total assets and € 1,184 bn customer deposits + mutual funds.
The client’s goal is to be the best open financial services platform, by responsible action and earning the meaningful trust of all stakeholders – people, customers, shareholders, and communities.
The challenge
In large, regulated financial institutions, data is generated and managed across countless systems and business domains. Over time, each system and domain develops its own logic, storage rules, and access controls. When such complexity accumulates, even simple analytical tasks require navigating multiple, often inconsistent data sources. Without a unified approach to data management, banks face rising operational costs, longer delivery times, and greater compliance risks.
In Santander’s case, it translated into several concrete challenges:
- Fragmented data and inconsistent standards
Multiple source systems and local rules (including different retention horizons per table or domain) made cross-functional reporting and analytics slow and error-prone. Business users struggled to get a single, reliable view. - Constantly evolving business requirements
Definitions, processing rules, and data scope changed frequently. Each change required engineering effort, creating backlogs and lengthening time-to-value for new use cases. - Strict privacy, security, and audit expectations
The bank needed enforceable, transparent controls over personal data – who can see what, how it is masked or anonymized, and when it must be removed – while preserving analytical usefulness. - Operational efficiency at scale
Growing data volumes and mixed ingestion patterns (batch and near-real-time) exposed the limits of manual orchestration and bespoke jobs, increasing operational overhead and elongating lead times for onboarding new feeds.
These challengess are typical across the financial sector; they differ in magnitude, not in nature. Critically, the absence of a deliberate enterprise data strategy compounds over time: duplicated logic, conflicting definitions, and ad hoc retention rules accumulate into technical debt. The earlier an institution standardizes on a governance-driven, configuration-first approach, the faster it can reduce risk, accelerate delivery, and keep pace with regulatory and market change.
The solution
To address the complexity of Santander’s data ecosystem, BitPeak designed and implemented a configuration-driven framework within the bank’s The goal was to create a unified, automated process for ingesting, transforming, and securing data coming from multiple banking systems – while maintaining full regulatory compliance and business flexibility.
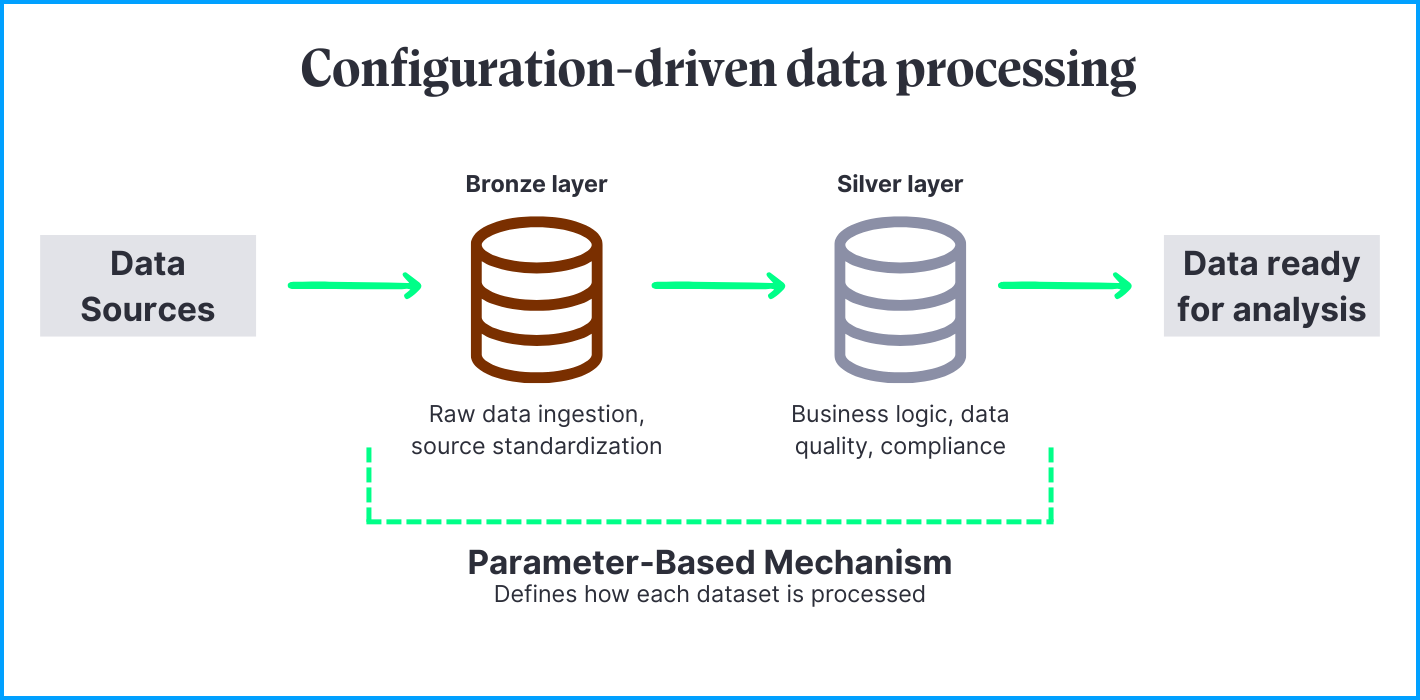
The solution was built on the Databricks platform and operates across the Bronze and Silver layers of Santander’s Cloud Data Lake.
- The Bronze layer serves as a controlled entry point for raw data arriving from diverse sources. It standardizes ingestion formats and ensures traceability from origin to target.
- The Silver layer applies business logic, quality rules, and compliance mechanisms – including automated anonymization and retention policies – ensuring that every dataset entering the analytical environment is verified and compliant by design.
At the core of this architecture lies an advanced parameter-based mechanism, configured and refined by BitPeak, which defines how each dataset should be processed. Building on existing capabilities, the team adjusted the mechanism to align with Santander’s internal systems, business logic, and regulatory requirements. Instead of hard-coded transformations, data engineers and business teams manage processing logic through configurations stored in metadata or specific templates, allowing our client to update business rules, retention periods, or anonymization criteria without time-consuming code changes or redeployments.
By embedding governance and automation directly into the data pipeline, the framework eliminates manual intervention, increases transparency, and reduces operational overhead. Data from previously isolated systems can now be integrated and processed through one consistent framework – enabling faster onboarding of new sources, better control over sensitive information, and a significant reduction in delivery time for analytical initiatives.
We ensured the parameter-based mechanism aligned with the bank’s and its business units’ individual needs. Ultimately, the solution provides Santander with a scalable and compliant foundation for data processing – one that simplifies operations today while laying the groundwork for future expansion of analytical and regulatory use cases across the organization.
To reach our goal, we used the following tech stack:
- Azure Cloud & Databricks Platform – core environment for building and orchestrating the configuration-driven framework within Santander’s Cloud Data Lake.
- Databricks Spark SQL & Databricks Connect – used to validate data structures and ensure correct processing across Bronze and Silver layers.
Benefits:
Strategy
The new framework provides Santander with a unified, scalable foundation for data-driven decision-making. By centralizing data processing within the Cloud Data Lake and embedding compliance into every step, the bank can expand its analytical capabilities with confidence. The configuration-driven approach also reduces long-term costs by standardizing development patterns and minimizing duplication of logic across departments.
Management
Automated orchestration and configuration-based processing significantly shortened deployment timelines and simplified change management. New data sources can now be onboarded within days instead of weeks, while operational teams spend less time on maintenance and manual corrections. The framework’s transparency and traceability improve audit readiness and governance reporting across the organization.
Business Users
For business users and data owners, the solution introduced greater control and independence in managing data transformations. Thanks to the metadata-driven configuration layer, teams can define or adjust processing rules without writing code, enabling faster adaptation to new analytical needs, more efficient reporting, and better alignment between data assets and business priorities.







