+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
In today’s digital landscape, the management and analysis of textual data have become integral to numerous fields, particularly in the context of training language models like Large Language Models (LLMs) for various applications. Chunking, a fundamental technique in text processing, involves splitting text into smaller, meaningful segments for easier analysis.
While traditional methods based on token and sentence counts provide initial segmentation, semantic chunking offers a more nuanced approach by considering the underlying meaning and context of the text. This article explores the diverse methodologies of chunking and aims to guide readers in selecting the most suitable chunking method based on the characteristics of the text being analyzed. The importance of this is particularly evident when utilizing LLMs to create RAGs (Retrieval-Augmented Generative models). Additionally, it dives into the intricacies of semantic chunking, highlighting its significance in segmenting text without relying on LLMs, thereby offering valuable insights into optimizing text analysis endeavors.
Understanding Chunking
Chunking, in its essence, involves breaking down a continuous stream of text into smaller, coherent units. These units, or „chunks,” serve as building blocks for subsequent analysis, facilitating tasks such as information retrieval, sentiment analysis, and machine translation. The effectiveness of chunking is particularly important in crafting RAG (Retrieval-Augmented Generation) models, where the quality and relevance of the input data significantly impact model performance. This happens because different embedding models have different maximum input lengths. While conventional chunking methods rely on simple criteria like token or sentence counts, semantic chunking takes a deeper dive into the underlying meaning of the text, aiming to extract semantically meaningful segments that capture the essence of the content.
Key concepts
Before diving into the main body of the article, it’s worth getting to know a few definitions/concepts.
Text embeddings
Text embeddings are numerical representations of texts in a high-dimensional space, where texts with similar meanings are closer to each other. In this space, each dimension corresponds to a word or token from the vocabulary. These representations capture semantic relationships between texts, allowing algorithms to understand language semantics.
Figure 1 Word embeddings - Source.
Cosine similarity
Cosine similarity is a measure frequently employed to assess the semantic similarity between two embeddings. It operates by computing the cosine of the angle between two vector embeddings that represent these sentences in a high-dimensional space. These vectors can be represented in 2 ways:
You can find more information about the differences between sparse and dense vectors here. This similarity measure evaluates the alignment or similarity in direction between the vectors, effectively indicating how closely related the semantic meanings of the sentences are. A cosine similarity value of 1 suggests perfect similarity, implying that the semantic meanings of the sentences are identical, while a value of 0 indicates no similarity between the sentences, signifying completely dissimilar semantic meanings. Additionally, an exemplary calculation along with an explanation is well presented in following video.
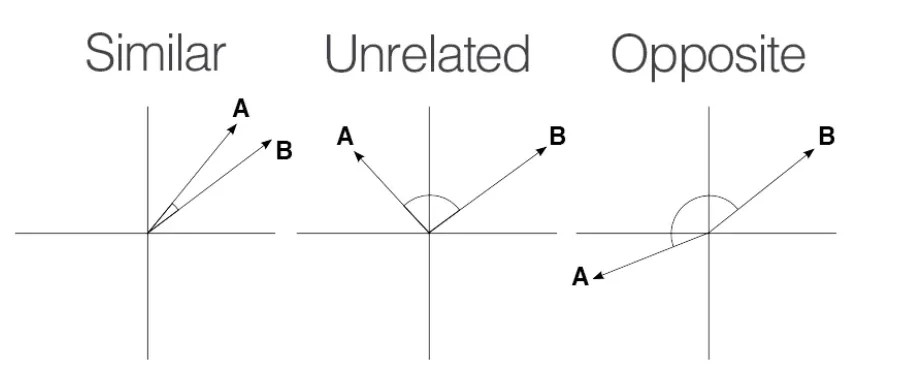
Figure 2 Sample visualization of cosine similarity - Source.
LLM’s context window
In Language Modeling (LLM), a context window refers to a fixed-size window that is used to capture the surrounding context of a given word or token in a sequence of text. This context window defines the scope within which the model analyzes the text to predict the next word or token in the sequence. By considering the words or tokens within the context window, the model captures the contextual information necessary for making accurate predictions about the next element in the sequence. It’s important to note that various chunking methods may behave differently depending on the size and nature of the context window used. The size of the context window is a hyperparameter that can be adjusted based on the specific requirements of the language model and the nature of the text data being analyzed. For more information about context window check this article.
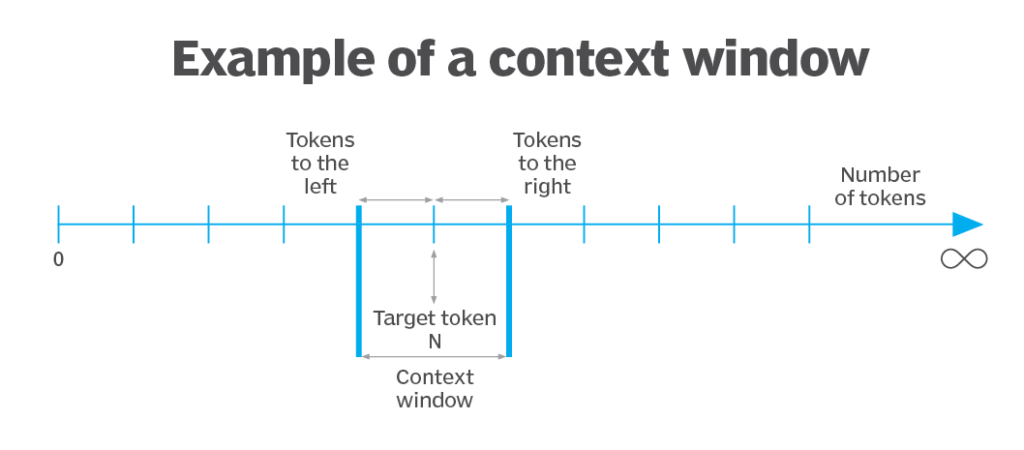
Figure 3 Sample visualization of context window - Source.
Conventional chunking methods
Among chunking methods, two main subgroups can be identified. The first group consists of conventional chunking methods, which split the document into chunks without considering the meaning of the text itself. The second group consists of semantic chunking methods, which divide the text into chunks through semantic analysis of the text. The diagram below illustrates how to distinguish between various methods
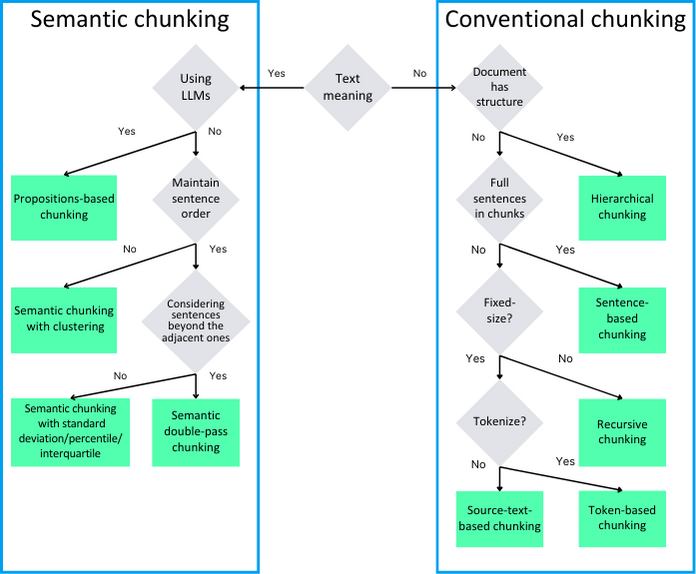
Figure 4. Diagram representing the difference between the selected types of chunking.
Source-text-based chunking
Source-text-based chunking involves dividing a text into smaller segments directly based on its original form, disregarding any prior tokenization. Unlike token-based chunking, which relies on pre-existing tokens, source-text-based chunking segments the text purely based on its raw content. This method allows for segmentation without consideration of word boundaries or punctuation marks, providing a more flexible approach to text analysis. Additionally, source-text-based chunking can employ a sliding window technique.
This involves moving a fixed-size window across the original text, segmenting it into chunks based on the content within the window at each position. The sliding window approach facilitates sequential segmentation of the text, capturing local contextual information without relying on predefined token boundaries. It aims to capture meaningful units of text directly from the original source, which may not necessarily align with token boundaries. However, a drawback is that language models typically operate on tokenized input, so text divided without tokenization may not be an optimal solution.
It’s worth mentioning that LangChain has a class named CharacterTextSplitter, which might suggest splitting text character by character. However, this is not the case, as this function splits the text based on the regex provided by the user (e.g., by space or newline characters). This is because each splitter in LangChain inherits from the text_splitter class, which takes chunk_size and overlap as arguments. Subclasses override the split_text method in a way that may not utilize the parameters contained in the base class.
Token-based chunking
Token-based chunking is a text processing method where a continuous stream of text is divided into smaller segments using predetermined criteria based on tokens. Tokens, representing individual units of meaning like words or punctuation marks, play a crucial role in this process. In token-based chunking, text segmentation occurs based on a set number of tokens per chunk. An important consideration in this process is overlapping, where tokens may be shared between adjacent chunks.
However, when chunks are relatively short, significant overlap can occur, leading to a higher percentage of repeated information. This can result in increased indexing and processing costs for such chunks. While token-based chunking is straightforward and easy to implement, it may overlook semantic nuances due to its focus on token counts rather than the deeper semantic structure of the text. Nonetheless, managing overlap is essential to balance the trade-off between segment coherence and processing efficiency. This function is built into popular libraries LlamaIndex and LangChain.
Sentence-based chunking
Sentence-based chunking is a fundamental approach in text processing that involves segmenting text into meaningful units based on sentence boundaries. In this method, the text is divided into chunks, with each chunk encompassing one or more complete sentences. This approach leverages the natural structure of language, as sentences are typically coherent units of thought or expression. Sentence-based chunking offers several advantages, including facilitating easier comprehension and analysis by ensuring that each chunk encapsulates a self-contained idea or concept. Moreover, this method provides a standardized and intuitive way to segment text, making it accessible and straightforward to implement across various text analysis tasks.
However, sentence-based chunking may encounter challenges with complex or compound sentences, where the boundaries between sentences are less distinct. In such cases, the resulting chunks may vary in length and coherence, potentially impacting the accuracy and effectiveness of subsequent analysis. Despite these limitations, sentence-based chunking remains a valuable technique in text processing, particularly for tasks requiring a clear and structured segmentation of textual data. Sample implementation is available in nltk.tokenize.
Recursive chunking
Recursive chunking is a text segmentation technique that employs either token-based or source-text-based chunking to recursively divide a text into smaller units. In this method, larger chunks are initially segmented using token-based or source-text-based chunking techniques. Then, each of these larger chunks is further subdivided into smaller segments using the same chunking approach. This recursive process continues until the desired level of granularity is achieved or until certain criteria are met. Its drawback is computational inefficiency.
Hierarchical chunking
Hierarchical chunking is an advanced text segmentation technique that considers the complex structure and hierarchy within the text. Unlike traditional segmentation methods that divide the text into simple fragments, hierarchical chunking examines relationships between different parts of the text. The text is divided into segments that reflect various levels of hierarchy, such as sections, subsections, paragraphs, sentences, etc. This segmentation method allows for a more detailed analysis and understanding of the text structure, which is particularly useful for documents with complex structures such as scientific articles, business reports, or web pages.
Hierarchical chunking enables the organization and extraction of key information from the text in a logical and structured manner, facilitating further text analysis and processing. An advantage of hierarchical chunking is its ability to effectively group text segments, particularly in well-formatted documents, enhancing readability and comprehension. However, a drawback is its susceptibility to malfunction when dealing with poorly formatted documents, as it relies heavily on the correct hierarchical structure of the text. LangChain comes with many built-in methods for hierarchical chunking, such as MarkdownHeaderTextSplitter, LatexTextSplitter, and HTMLHeaderTextSplitter.
Semantic chunking methods
Semantic chunking is an advanced text processing technique aimed at dividing text into semantically coherent segments, taking into account the meaning and context of words. Unlike traditional methods that rely on simple criteria such as token or sentence counts, semantic chunking utilizes more sophisticated techniques of semantic analysis to extract text segments that best reflect the content’s meaning. To perform semantic chunking, various techniques can be employed. As a result, semantic chunking can identify text segments that are semantically similar to each other, even if they do not appear in the same sentence or are not directly connected.
Clustering with k-means
Semantic chunking using k-means involves a multi-step process. Firstly, sentence embeddings need to be generated using an embedding model, such as Word2Vec, GloVe, or BERT. These embeddings represent the semantic meaning of each sentence in a high-dimensional vector space. Next, the k-means clustering algorithm is applied to these embeddings to group similar sentences into clusters. Implementing semantic chunking with k-means requires a pre-existing embedding model and expertise in NLP and machine learning. Additionally, selecting the optimal number of clusters (k) is challenging and may necessitate experimentation or domain knowledge.
One significant drawback of this approach is the potential loss of sentence order within each cluster. K-means clustering operates based on the similarity of sentence embeddings, disregarding the original sequence of sentences. Consequently, the resulting clusters may not preserve the chronological or contextual relationships between sentences. We strongly advise against using this method for text chunking when constructing RAGs. It leads to the loss of meaning in the processed text and may result in the retriever returning inaccurate content.
Propositions-based chunking
This chunking strategy explores leveraging LLMs to discern the optimal content and size of text chunks based on contextual understanding. At the beginning, the process involves creating so-called “propositions”, often facilitated by tools like LangChain. Propositions are defined as atomic expressions within text, each encapsulating a distinct factoid and presented in a concise, self-contained natural language format.
These propositions are then passed to an LLM, which determines the optimal grouping of propositions based on their semantic coherence. Performance of this approach heavily depends on the language model the user chooses. Despite its effectiveness, a drawback of this approach is the high computational costs incurred due to the utilization of LLMs. Extensive explanation of this method is in this article and a modified proposal is presented in this tweet.
Standard deviation/percentile/interquartile merging
This semantic chunking implementation utilizes embedding models to determine when to segment sentences based on differences in embeddings between them. It operates by identifying differences in embeddings between sentences, and when these differences exceed a predefined threshold, the sentences are split. Segmentation can be achieved using percentile, standard deviation, and interquartile methods. A drawback of this approach is its computational complexity and the requirement for an embedding model. This algorithm’s implementation is available in LlamaIndex. Greg Kamradt showcased this idea in one of his tweets.
Double-pass merging (our proposal)
Considering the challenges faced by semantic chunking using various mathematical measures (standard deviation/percentile/interquartile), we propose a new approach to semantic chunking. Our approach is based on cosine similarity, and the initial pass operates very similarly to the previously described method. What sets it apart is the application of a second pass aimed at merging chunks created in the first pass into larger ones. Additionally, our method allows for looking beyond just the nearest neighbor chunk.
This is important when the text, which may be on a similar topic, is interrupted with a quote (which semantically may differ from the surrounding text) or a mathematical formula. The second pass examines two consecutive chunks: if no similarity is observed between the two neighbors, it checks the similarity between the first and third chunks being examined. If these two chunks are classified as similar, then all three chunks are merged into one. A detailed description of the algorithm and code will be presented in an upcoming article, which will be published shortly.
Summary
As you can see there are many diverse chunking algorithms differing in various aspects such as required computational power, costs, duration, and implementation complexity. Selection of an appropriate chunking algorithm is an important decision as it impacts two key factors of the solution: quality of final results (quality of answers generated by RAG) and cost of running it. Therefore, it should be preceded by a thorough analysis of, amongst others, the purpose for which the chunking is to be performed and quality of source documents. Our next article comparing the performance of various chunking methods can be helpful with taking a decision. Stay tuned!
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.