
 +48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
Databricks compute is a complex and deep topic, especially when considering the fact that the platform changes over time dynamically. Therefore, we would like to share a little know-how about choices that need to be made when deciding between compute approaches in specific use cases. Additionally, we will look over some compute management options not omitting serverless.
So, take a Peak at an article below and learn a Bit with our Databricks Architect Champion.
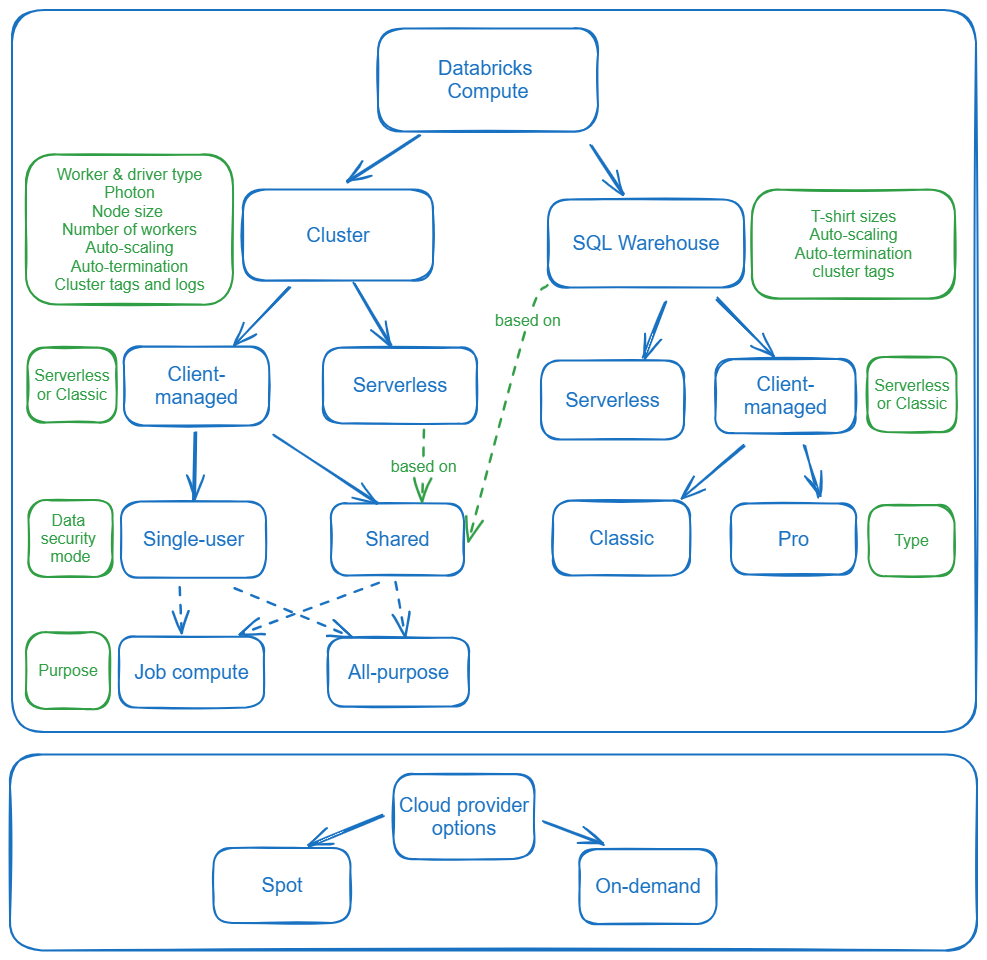
Job and all-purpose clusters
The all-purpose clusters are designed for interactive/collaborative usage in development, ad-hoc analysis, and data exploration while job clusters run to execute a specific, automated job after which they immediately release resources.
In case you need to provide immediate availability of a job cluster (for example for jobs that run very frequently and you cannot afford the ca. 5-minute startup time) consider using cluster pools and having a number of idle instances greater than 0.
Spot instances
Spot instances (VMs) make use of the available compute capacity of a cloud provider with deep discounts. Databricks manages termination and startup of spot workers, so that the defined number of cores is reached and available for the cluster. Any time when cloud provider needs the capacity the machine is evicted, if you enable decommissioning – with an earlier notice. For Azure the notification is sent 30 seconds before the actual eviction (Use Azure Spot Virtual Machines – Azure Virtual Machines | Microsoft Learn).
spark.storage.decommission.enabled true
spark.storage.decommission.shuffleBlocks.enabled true
spark.storage.decommission.rddBlocks.enabled true
Using the above Spark configuration you can try to mitigate negative results of compute node eviction. The more data is migrated to the new node the less likely are the errors from shuffle fetching failures, shuffle data loss and RDD data loss. Even if a worker fails, Databricks manages its replacements and minimizes the impact on your workload. Of course, the driver is critical and should be kept as on-demand instance.
Databricks states decommissioning is a best effort so it’s better to choose on-demand instances for crucial production jobs with tight SLAs.
You can setup spot instances via Databricks UI but more options are available when using Databricks REST API (Create new cluster | Clusters API | REST API reference | Azure Databricks, azure_attibutes object), e.g., how many first nodes of the cluster (including driver) are on-demand, fallback option (you can choose to fall back to on-demand node), as well as the maximum spot price.
The spot price and a rough estimate of eviction rate for a region can also be checked in “Create a virtual machine” screen. For example, for West Europe region the eviction rate is 0-5%.
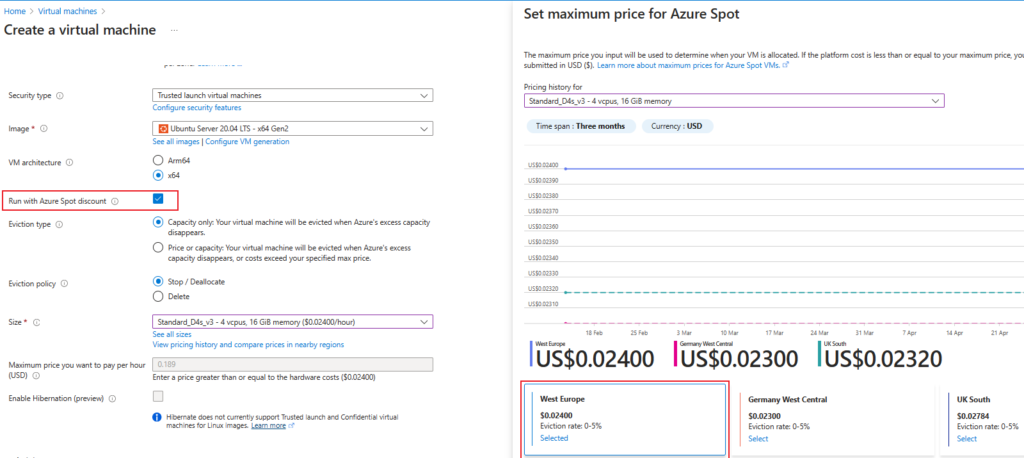
It is important to note though, that storage and network IO are billed independently of the chosen option, at a regular price.
Single user or shared access mode
The single-user cluster is assigned to and can be used by only one user at a time while shared clusters are designed to be used by multiple users simultaneously thanks to the session and data isolation.
Both access modes work with Unity Catalog although the main limitation of the single-user cluster is that it cannot query tables created within UC-enabled DLT pipelines (also including materialized views created in Databricks SQL). To query such tables, you must use a shared compute.
There are still significantly more limitations on shared clusters due to the fact that these clusters need to provide session isolation between users and prevent them from accessing data without proper UC permissions (e.g., bypassing through DBUtils tools and accessing cloud storage directly):
- You cannot manipulate with DBUtils, RDD API or Spark Context (instead you should use Spark Session instance).
- Spark-submit jobs are not supported.
- Language support: Scala supported on DBR 13.3 and above, no support for R.
- Streaming limitations: unsupported options for Kafka sources and sinks, Avro data requires DBR 14.2 or above, new behavior for foreachBatch in DBR 14.0 and above.
- No support for Databricks Runtime ML and Spark ML Library (MLib).
For comprehensive information on limitations consult Databricks documentation.
Databricks recommends using shared access mode for all workloads. The only exception to use the single-user access mode should be if your required functionality is not supported by shared access mode.
Cluster node type
When choosing node type for driver and worker you need to consider the performance factors which are most accurate for your specific job.
A cluster has the following factors determining performance:
- Total executor cores: total number of cores across all workers; determines the maximum parallelism of a job.
- Total executor memory: total amount of RAM across all workers; determines how much data can be stored in memory before spilling it to disk.
- Executor local storage: the type and amount of local disk storage; Local disk is primarily used in the case of spills during shuffles and caching.
A good practice is to provide a separate cluster or cluster pools for different groups of interest. Depending on the workload to be run on a cluster you can configure memory and cores appropriately:
- Ad-hoc analysis – Data analysts cluster’s main purpose is to pull, aggregate data, and report on it. SQL analysts use repetitive queries which often involve shuffle (wide) operations like joins or grouping. Therefore, both memory as well as local storage will be crucial factors. Consider using memory- or storage-optimized (with Delta caching) node types which will support repetitive queries to the same sources. There might be significant time gaps between running subsequent queries hence the cluster should have reasonable auto-termination minutes configured.
- Training ML Models – Data scientists often need to cache full dataset to train the model. Hence, memory and caching are in high demand. In some cases, they might also need GPU-accelerated instance types to achieve highly parallelized computations. Therefore, the chosen compute type could either be storage-optimized or GPU-optimized compute.
- For batch ETL pipelines the amount of memory and compute can be fine-tuned. Based on spark.sql.files.maxPartitionBytes setup (128 MB by default) as well as size of the underlying files we can estimate how many partitions will be created and assign an appropriate number of cores depending on parallelism and SLA we need to provide. If ETL jobs involve full file scans with no data reuse we should be good with compute-optimized instance types.
- Streaming jobs usually have priority to compute and IO throughput over memory. Hence, compute-optimized instances might be a good choice. In case of streaming jobs of high importance, the cluster should be designed to provide fault tolerance in case of executor failures, so opt to choose more than one executor.
If workers are involved in heavy shuffles (due to wide transformations) you should also limit the number of executors, i.e., rather have more cores on one executor than having more executors with a small number of cores. Otherwise, you will put significant pressure on network IO which will slow down the job.
On the other hand, if an executor has a large amount of RAM configured this can lead to longer garbage collection times. Therefore, it should be tested when optimizing the size of the executor node whether you see any performance degradation after choosing a small number of workers.
When choosing a machine type you can also take a look at VM price comparisons on CloudPrice website (Azure, AWS, GCP Instance Comparison | CloudPrice) but remember that this is only what you pay to the cloud vendor for the VM. For example, even if a machine is shown here as a cheaper option you need to take into account also if it doesn’t incur higher DBUs costs as well as possibly a higher price for disk, if you change to an SSD-equipped machine.
Compute management
It is recommended to limit users’ ability to create their own fully-configurable clusters. Make sure you do not allow “Unrestricted cluster creation” to users or user groups unless they are privileged users. Instead, you can create several cluster policies addressing the needs of different groups of users (e.g., data engineers, SQL analysts, ML specialists) and grant CAN_USE permission to the respective groups.
You can control (i.e., hide or fix) multitude of cluster attributes. To name just a few:
- Auto-termination minutes
- Maximum number of workers
- Maximum DBUs per hour
- Node type for driver and worker
- Attributes related to chosen availability type: on-demand or spot instances
- Cluster log path
- Cluster tags
With cluster policies each user can create their own cluster, if they have any cluster policy assigned, and each cluster has its separate limit for the compute capacity.
If there is a need to further restrict users, you can also limit users’ ability to create a cluster (assigning only CAN RESTART or CAN ATTACH TO permissions) and force users to only run their code on pre-created clusters.
Photon
In some cases Photon can significantly reduce job execution time leading to overall lower costs, especially considering data modification operations.
A valid case is when we would like to leverage dynamic file pruning in MERGE, UPDATE, and DELETE statements (which includes apply_changes in DLT world). Note that only SELECT statements can use this feature without Photon-enabled compute. This might improve performance, especially for non-partitioned tables.
Another performance feature conditioned by Photon is predictive IO for reads and writes (leveraging deletion vectors). Predictive IO employs deletion vectors to enhance data modification performance: instead of rewriting all records within a data file whenever a record is updated or deleted, deletion vectors are used to signal that certain records have been removed from the target data files. Supplemental data files are created to track updates.
Cluster tags and logs
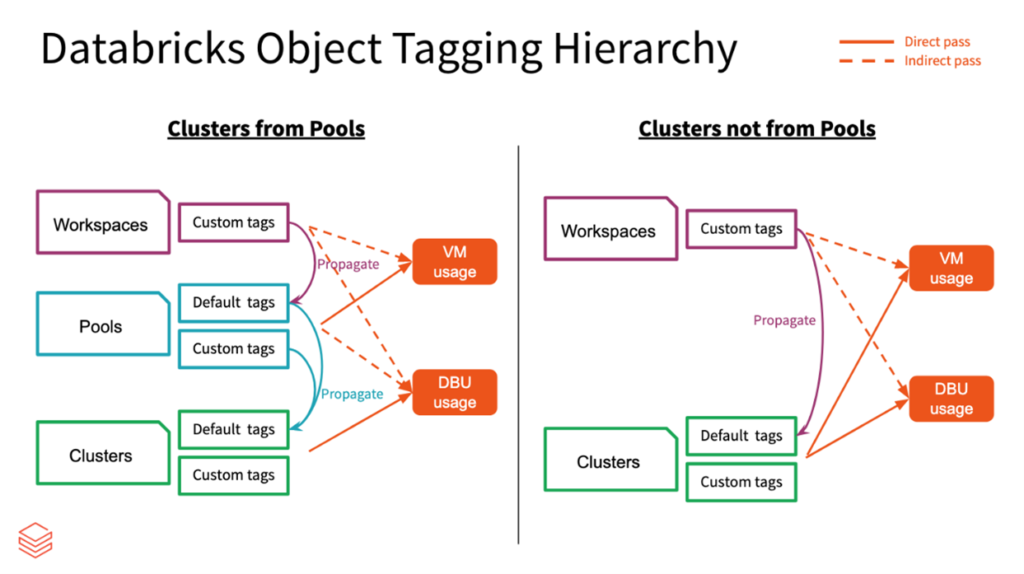
Last but not least, don’t forget to tag your clusters and cluster pools.
As you can see from the following graph tags from cluster pools will appear on associated cloud resources as well as are propagated to clusters created from that pool providing basis for DBU usage reporting. Hence, it is crucial, when using cluster pools, to pay attention to their tagging.
The tags are applied to cloud resources like VMs and disk volumes, as well as DBU usage reports.
You might also consider specifying a location on DBFS (Databricks on AWS also support S3) to deliver the logs for the Spark driver node, worker nodes, and events, so that you can analyze the logs in case of failures or issues. The logs are stored for up to 30 days.
Serverless
As our article is meant to provide an overview of compute, we definitely cannot skip serverless which is becoming increasingly significant in Databricks environment.
Security
First concern when it comes to serverless is security.
Enterprises may have security issues with the compute running inside of Databricks cloud provider subscription (and not in customer’s virtual network).
Therefore it is important to take note of the available security features for serverless.
First of all, connection to storage goes always over cloud network backbone and not over public internet.
Secondly, you can enable Network connectivity configuration (NCC) on your Databricks account and assign it to your workspaces. You can choose either one of the two options to secure access to your storage accounts:
- Using resource firewall: NCC enables Databricks-managed stable Azure service subnets which you can add to your resource firewalls
- Using private endpoints: the private endpoint is added to an NCC in Databricks account and then the request needs to be accepted on the resource side.
Also, when considering serverless review the compute isolation and workload protection specification: Deploy Your Workloads Safely on Serverless Compute | Databricks
Serverless usage
Databricks serverless compute is definitely in expansion phase taking into consideration public preview features like serverless compute for workflows and notebooks as well as DLT serverless in private preview.
Here is a quick overview of the serverless compute features:
- Fully managed compute,
- Instant startup, usually ca. 5-10 seconds
- Automated optimizing and scaling: selecting appropriate resources such as instance types, memory and processing engines,
- Photon automatically enabled,
- Automated retry of failed jobs (serverless compute for workflows),
- Automated upgrades of Databricks Runtime version,
- Based on shared compute security mode. Hence, all limitations of shared compute apply,
- Serverless comes with pre-installed libraries (Serverless compute release notes – Azure Databricks | Microsoft Learn) but there is also an option to define your environment or install libraries in the notebook using pip,
- Public preview of serverless compute does not support controlling egress traffic and therefore you cannot set up an egress IP (jobs have full access to the internet),
- No cloud provider costs (only Databricks costs based on DBUs) but companies may not be able to leverage their existing cloud discount.
There is an obvious trade-off between having control over compute configuration and a fully-managed service that serverless is: you lose the ability to optimize the cluster and adjust instance types for your specific workload as well as you cannot choose the Databricks Runtime, which may result in compatibility issues.
Summary
As you can see, Databricks compute configuration presents pletora of options with which you can configure it to your needs. Each one has its advantages and disadvantages. Hopefully with this article you will be better equipped to wade through the settings and choose the best, most cost efficient option.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.







