+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
Data Vault, compared to other modelling methods is relatively new. There are not many specialists with experience when it comes to data warehouses in this architecture. The lack of practical knowledge often results in solutions that only partially comply with the guidelines. This results in achieved results not fulfilling expectations and not supporting business strategy properly. Implementation and performance are especially problematic and require in-depth consideration.
But if you are curious about enormous potential of Data Vault as a Data Governance tool – you came to right place. As a Senior Data Engineer and Data Governance expert with several years of experience in implementing and developing Data Vaults, I’ve decided to write down the most vital issues to consider while building DV in your organization. Issues such as the implementation of modelling from the architecture level to the physical fields in the warehouse. We are sure that they will help anyone who considers a warehouse in a Data Vault architecture.
The article is mostly for people who have some experience in dealing with databases and data warehouses before. It does not explain the basics of creating a data warehouse, modeling, foreign keys, or what SCD1 and SCD2 are. For those unfamiliar with the concepts, the article may be a challenging lecture. However, for those well-versed in dealing with databases and data warehouses, or just determined and able to access the google – this will most certainly be a very valuable lecture.
What is Data Vault?
Data Vault is a set of rules/methodologies that allow for the comprehensive delivery of a modern, scalable data warehouse. Importantly, these methodologies are universal. For example, they allow for modeling both financial data warehouses where data is loaded on a daily basis, and where backward data corrections are important, as well as warehouses collecting user behavioral data loaded in micro-batches. Data Vault precisely defines the types of objects in which data is physically stored, how to connect them, and how to use them. Thanks to these rules, we can create a high-performance (in terms of reading and writing) fully scalable (in terms of computing power, space, and surprisingly, also manufacturing!) data warehouse. Proper use of Data Vault enables us to fully leverage the scaling capabilities of Cloud, Big Data, Appliance, RDBMS environments (in terms of space and computing power). Additionally, the structure of the model and its flexibility allows for parallel development of the data warehouse model by multiple teams simultaneously (e.g., in the Agile Nexus model).
The two logical layers of the integrated Data Vault model are:
- Raw Data Vault – raw data organized based on business keys (BKEY) and „hard rules” transformations (explained later in the article).
- Business Data Vault – transformed and organized data based on business rules.
Both layers can physically exist in one database schema, and it’s important to manage the naming convention of objects appropriately. An issue which I will explain later. The Information Delivery layer (Data Marts) should be built on top of the above layers in a way that corresponds to the business requirements. It doesn’t have to be in the Data Vault format, so I won’t focus on Information Delivery design in this article.
Currently, Data Vault is most popular in Scandinavian countries and the United States, but I believe it is a very good alternative to Kimball and Immon and will quickly gain popularity worldwide.
Data Vault is „Business Centric” data model, which follows the business relationships rather than the systems and technical data structure in the sources. The data is grouped into areas, of which the central points are the so-called Hub objects (which will be discussed later). The technical and business timelines are completely separated. We can have multiple timelines because the time attributes in Data Vault are ordinary attributes of the data warehouse and do not have to be technical fields. On the other hand, Data Vault ensures data retention in the format in which the source system produced it, without loss or unnecessary transformations. It seems impossible to reconcile, yet it can be done.
Data Vault is a single source of facts, but the information an often be multi-faceted. Variants are necessary, because the same data is often interpreted differently by different recipients, and all these interpretations are correct. Facts are data as it came from the source; Such data can be interpreted in many ways, and with time, new recipients may appear for whom calculated values are incomplete. With time, the algorithms used for calculations may also degrade. Data Vault is fully flexible and prepared for such cases.
Data Vault is based on three basic types of objects/tables:
- Hub: stores only business keys (e.g. document number).
- Relational Link: contains relationships between business keys (e.g. connection between document number and customer).
- Satellite: stores data and attributes for the business key from the Hub. A satellite can be connected to either a Hub or a Link.
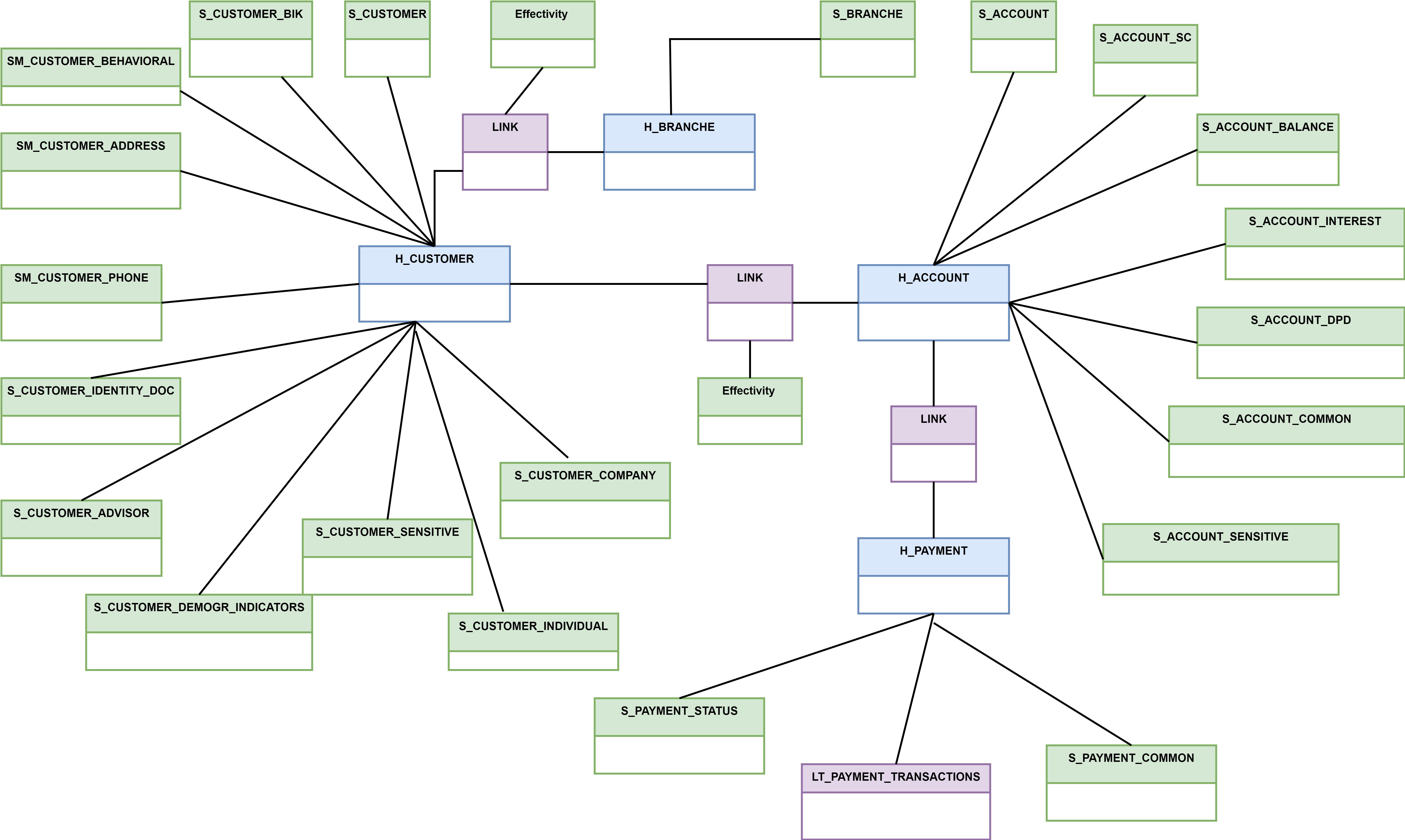
An example excerpt from a Data Vault model:
As you can see, the Data Vault model is not simple. Therefore, it is recommended to establish the appropriate rules for its development and documentation during the planning phase. It is also important to start modeling from a higher level. The best practice is to build a CDM (Corporate Data Model) in the company, which is a set of business entities and dependencies that function in the enterprise. The Data Vault model should refer to the high-level CDM in its detailed structure. Additionally, it is worth defining naming conventions for objects and columns. It is also necessary to document the model (e.g. in the Enterprise Architect tool).
Data Vault 2.0 – Architecture
In this article, we will focus only on the portion of the architecture highlighted on the diagram. To this end I will explain what the RDV and BDV layers are, how to model them logically and physically, and how to approach data modeling in relation to the entire organization. We will also discuss all types of Data Vault objects, good and bad practices for creating business keys, naming conventions, explain what passive integration is, and discuss hard rules and soft rules. I will try to cover all the key aspects of Data Vault, understanding of which enables the correct implementation of the data warehouse.
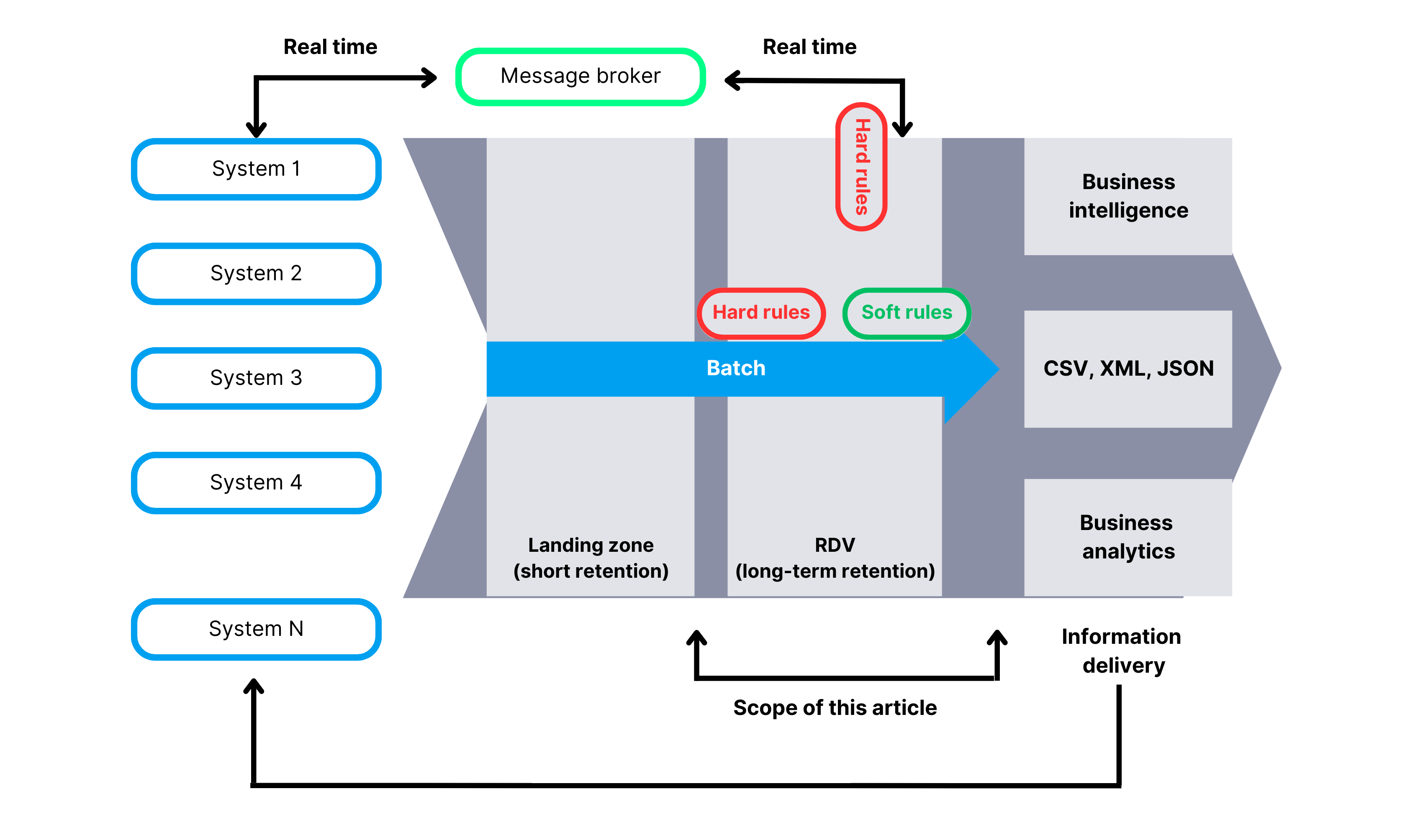
High-level diagram of a data warehouse architecture based on Data Vault.
Buisness hard and soft rules
A crucial aspect of a data warehouse is the storage and computation of facts and dimensions. To optimize this process, it’s very important to understand the differences between hard and soft rules transformations. Typically, the lower levels of any data warehouse store data in its least transformed state. This is due to practical considerations, as storing data in the form it was received in is crucial. Why? Because it allows us to use that data even after many years and calculate what we need at any given moment. On the other hand, some transformations are fully reversible and invariant over time, such as converting dates to the ISO format or converting decimal values from Decimal(14,2) to Decimal(18,4). These data transformations in Data Vault are called Hard Rules. Sometimes, we also consider irreversible transformations (for example trimming) as Hard Rules, but we must ensure that the data loss doesn’t have a business or technical impact. All other computations that involve column summation, data concatenation, dictionary-based calculations, or more complex algorithms fall under soft rule transformations. Data Vault clearly defines where we can apply specific transformations.
Raw Data Vault and Business Data Vault
In logical terms, the Data Vault model is divided into two layers:
Raw Data Vault (RDV) – Which contains raw data, with solely hard rules allowed for calculations. Despite this, the RDV model is fully business-oriented, with objects such as Hubs, Links, and Satellites arranged according to how the business understands the data. Technical data layouts, as found in the source system, are not allowed in this layer. This is known as the „Source System Data Vault (SSDV)”, which provides no benefits, such as passive model integration, which will be discussed later. This layer stores a longer history of data according to the needs of the data consumers. It is also a good practice to standardize the source system data types in this layer, for example, by having uniform date and currency formats.
Business Data Vault (BDV) – which allows for any type of data transformation (both hard and soft rules) and arranges the data in a business-oriented manner. The source of data for this layer is always the RDV layer. The fundamental rule of Data Vault is that the BDV layer can always be reconstructed based on the RDV layer. If all objects in the BDV layer are deleted, a well-constructed Data Vault model should allow for its re-population.
Both layers are accessible to users of the data warehouse and their objects can be easily combined. It is recommended to store tables from both the RDV and BDV layers in the same database (or schema) and differentiate them with an appropriate naming convention.
This concludes the first part of our articles about Data Vault and its implementation. Next week, you will be able to read about data modelling. To make sure you will not miss the next part of the series, be sure to follow us on our social media linked below. And if you have additional questions about data – let’s talk about it!
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.