+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
In the dynamically evolving world of Large Language Models (LLMs), the Retrieval Augmented Generation (RAG) technique is becoming increasingly popular and is emerging as a standard component in applications enabling users to converse with a language model on custom documents. Regarding the construction of RAGs, we have discussed what chunking is and the available chunking methods in our previous article. This time, we will examine tools for storing and querying vector embeddings.
There are numerous open-source tools and frameworks that facilitate the creation of RAGs based on private documents. One of them is LlamaIndex. One of the crucial aspects of developing RAGs is storing the documents themselves along with their vector embeddings in a database. Fortunately, LlamaIndex offers functionality that manages this for us, making it a desirable choice for storing data when dealing with a small number of documents. However, for a larger volume of documents intended for RAG creation, consideration should be given to a dedicated vector database. Again, LlamaIndex comes to the forefront with its integration capability with vector databases such as Chroma, which will also be discussed herein.
In this article, we focus on discussing the storage of custom documents using the LlamaIndex library. We explore and compare two approaches: one using the VectorStoreIndex and the other storing documents with embeddings in a Chroma collection. However, before we explore that topic, for a better understanding of the subject, let us briefly discuss how RAG works.
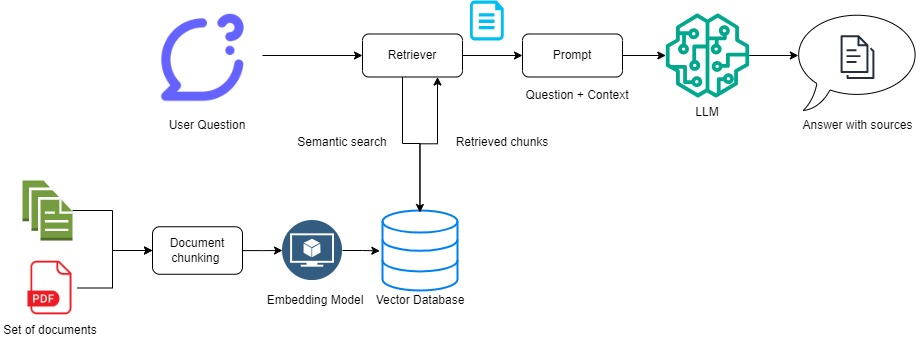
The diagram above represents a simple RAG architecture. The system operates by initially directing the user’s question to a Retriever, which scans a vector database to locate relevant information chunks potentially containing the answer. Utilizing predefined metrics, it matches the embedded question with stored embeddings through similarity matching. Subsequently, identified relevant chunks are merged with the original question to construct a Prompt. These retrieved chunks serve as the context for the LLM to generate the answer. Finally, the system delivers the response to the user, often referencing the sources or documents from which the information was retrieved. In the process of ingesting documents, they are parsed only once, chunked with the appropriate chunking method, and stored in the vector database as vector embeddings for further querying. This ensures that documents are not ingested repeatedly, but rather stored efficiently for quick retrieval. These documents can originate from diverse sources such as PDF files, plain text files, markdown, Confluence, URLs, etc.
LlamaIndex’s VectorStoreIndex
During the construction of a straightforward RAG architecture with a limited number of documents, the VectorStoreIndex comes into play. But what exactly is the VectorStoreIndex? According to the creators of the LlamaIndex library, it is one of the most prevalent forms of an Index, which is a data structure created from objects of the Document type to facilitate inquiries by the LLM. The utilization of VectorStoreIndex can be approached in two ways: high-level or low-level. Each has its advantages and drawbacks. But first, let us discuss what they entail.
High level approach
For each RAG architecture, documents must be loaded, parsed, and chunked in a certain way. If we have a small number of documents (for example: 5), we can use the SimpleDirectoryReader from LlamaIndex for this purpose. We can pass the full path to the folder containing all the files we want to read. It loads the documents from the given directory and returns them as a list of Document objects. Then, we provide them to the from_documents() method of VectorStoreIndex to create the Index – here our Documents are split into chunks and parsed to Node objects. In the final step, we call the as_query_engine() method on the Index, which creates the engine, and voila, we are able to query our documents. The described scenario is presented in the following code snippet:
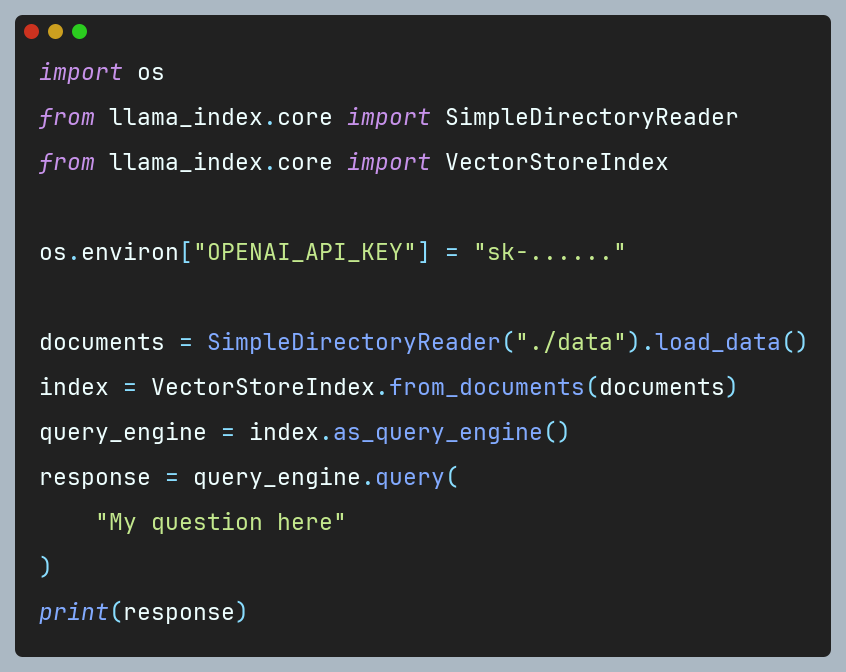
Despite the ability to swiftly and with minimal effort pose queries to documents, the utilization of VectorStoreIndex in this scenario is not flawless. Here, we suffer from a lack of control over the underlying processes, as VectorStoreIndex autonomously chunks documents and computes embeddings. This lack of control may lead to less satisfactory results and may not always meet the user’s expectations. Responses can be less accurate or contain often irrelevant information with respect to the initial question, therefore, a more hands-on approach might be necessary to ensure higher quality outcomes.
Low level approach
With a low-level approach, more effort is required, as we have the autonomy to directly decide how to load the data, parse it, and split it into chunks. Ready-made classes such as SentenceSplitter can be employed for this purpose, or one can implement their own chunking method, such as semantic chunking. Following this idea, we’ve implemented our own semantic chunking method called Semantic double-pass merging. We have described it in details and compared against another chunking methods in our article.
Assuming our data is loaded and transformed into chunks, we can utilize the insert() method of the VectorStoreIndex class to compute and store embeddings. However, it is essential to note that insert() requires a Document object as input, thus the chunks must be appropriately transformed. The following code snippet illustrates the described operation:
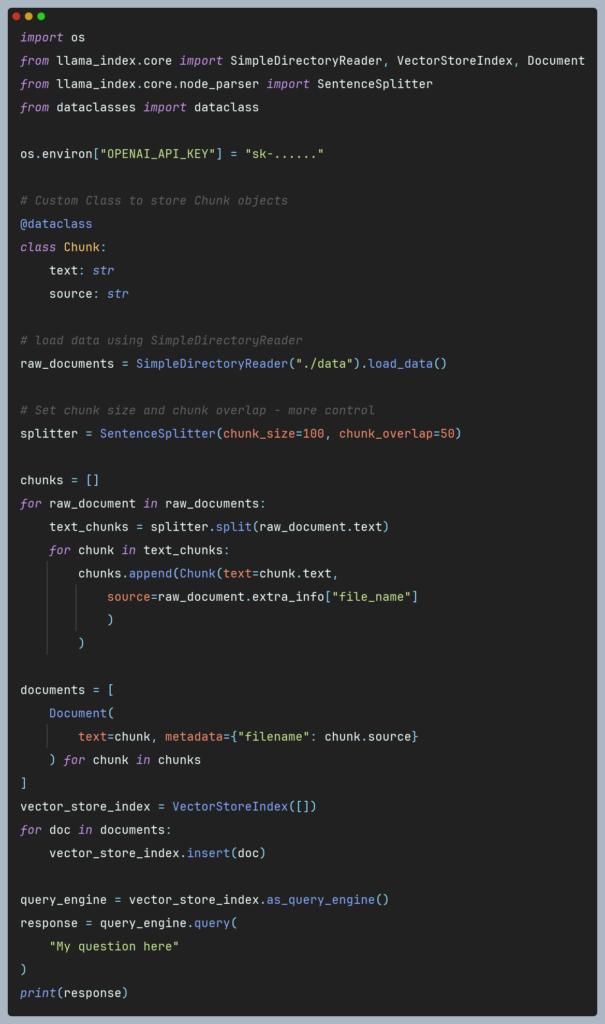
This approach is significantly more flexible, providing greater control over what gets stored in the vector storage. Nonetheless, it should be noted that it entails a greater workload, with proper chunking being a crucial aspect. Low level approach fits great with popular statement “with great power comes great responsibility” meaning that the programmer holds the reins to ensure the quality of responses by selecting the proper chunking method, thresholds, chunk sizes and other parameters. While this approach offers potential for higher quality responses, it does not guarantee it with absolute certainty. Instead, it allows the developer to optimize and tailor the process to specific needs, making the outcome dependent on the developer’s knowledge and decisions.
In both cases, embeddings are computed underneath by LlamaIndex, inherently utilizing the OpenAI text-embedding-ada-002 model. By default, indexed data is kept in memory, as is the case with the above examples. Often, there is a desire to persist with this data to avoid the time and cost of re-indexing it. Here, LlamaIndex helps with the persist() method, further details of which can be gleaned from the LlamaIndex documentation. Alternatively, one can leverage an external open-source vector database such as Chroma.
Chroma – open-source vector database
In the case of a larger quantity of documents beyond just a few individual PDF files, keeping them in memory may not be efficient. Developing RAG system may consume significantly more documents over time, resulting in excessive memory allocation. In terms of scalability, external vector databases designed for storing, querying, and retrieving similar vectors come to the rescue. Most open-source databases are integrated with libraries like LlamaIndex or LangChain, offering even simpler utilization. In this section, we examine the Chroma database (in the form of chromadb Python library) with LlamaIndex.
Within chromadb framework collections serve as a repository for embeddings. This library presents a range of methods for proficiently managing collections, encompassing creation, insertion, deletion, and querying functionalities. The instantiation of a specific collection necessitates the involvement of clients. In scenarios where one seeks to persist and retrieve their collection from a local machine, the PersistentClient class comes into play. Here, data automatically persisted and loaded upon startup if it already exists.
The chromadb library offers flexibility in terms of embeddings creation. Users have the option to create collections and provide only the relevant chunks, whereby the library autonomously calculates the embeddings. Alternatively, users can compute their own vectors embeddings using, for instance, a custom-trained embedding model, and then pass them to the collection. In the case of entrusting Chroma with the computation of embeddings, users can specify their chosen model through the embedding_function parameter during the collection creation process. Furthermore, users can provide their own custom function if they intend to calculate embeddings in a unique manner. If there is no embedding_function provided, Chroma will use all-MiniLM-L6-v2 model from SentenceTransformers as a default. For further insights, detailed information can be found in the chromadb documentation.
In our example, we will focus on embeddings previously computed using a different model. It is crucial that regardless of the method employed for generating embeddings (whether through Chroma or otherwise), they are created from appropriately chunked text. This practice significantly influences the quality of the resulting RAG system and its ability to answer questions effectively. The following code snippet demonstrates the creation of a collection and addition of documents with embedding vectors:
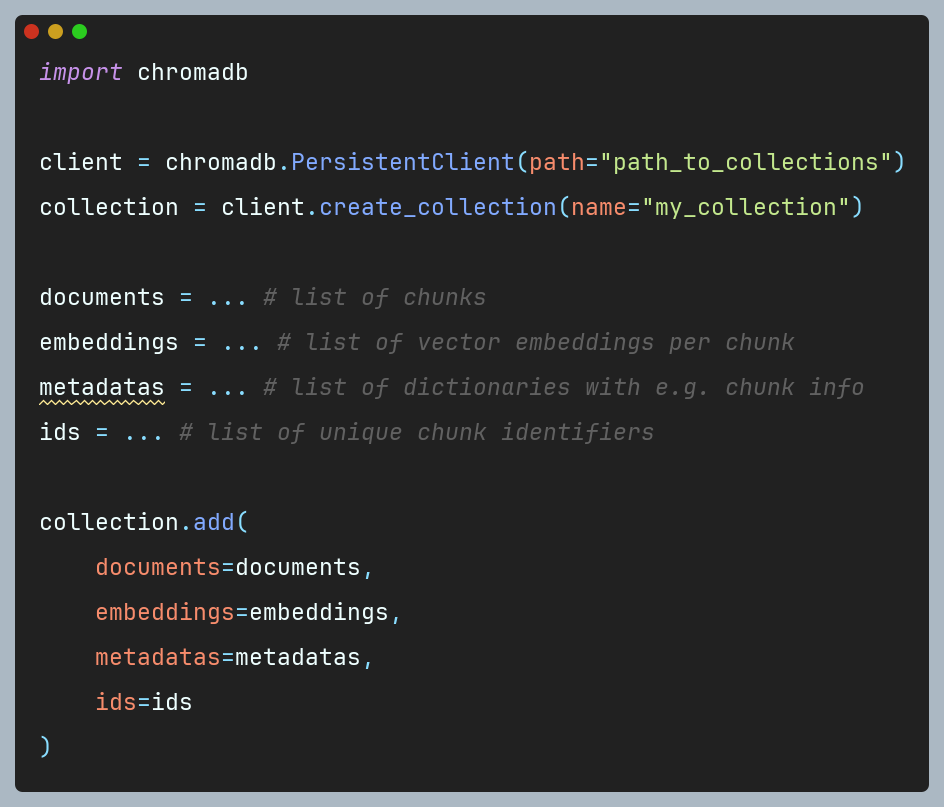
Chroma offers flexible storage of information within collections, accommodating both documents and their corresponding embeddings or standalone embeddings. Furthermore, by adding data to the collection using the add() method, one can specify a list of dictionaries in the metadatas argument, each corresponding to a particular chunk. This approach facilitates easy querying of the collection by referencing these metadata (further details on querying collections can be found in the documentation). This capability is particularly valuable for businesses needing to instantly search and retrieve the latest company-specific documents, thereby accelerating the process of finding nuances in documentation. As a result, it significantly enhances efficiency and decision-making, ensuring that critical information is readily accessible.
It is crucial to provide a list of document identifiers in the ids argument, as each document (chunk) must possess a unique ID. Attempting to add a document with the same ID will result in the preservation of the existing document in the collection (there is no overwrite functionality).
Once the collection with our embeddings is created, how can we use it with LlamaIndex? Let’s examine below code snippet:
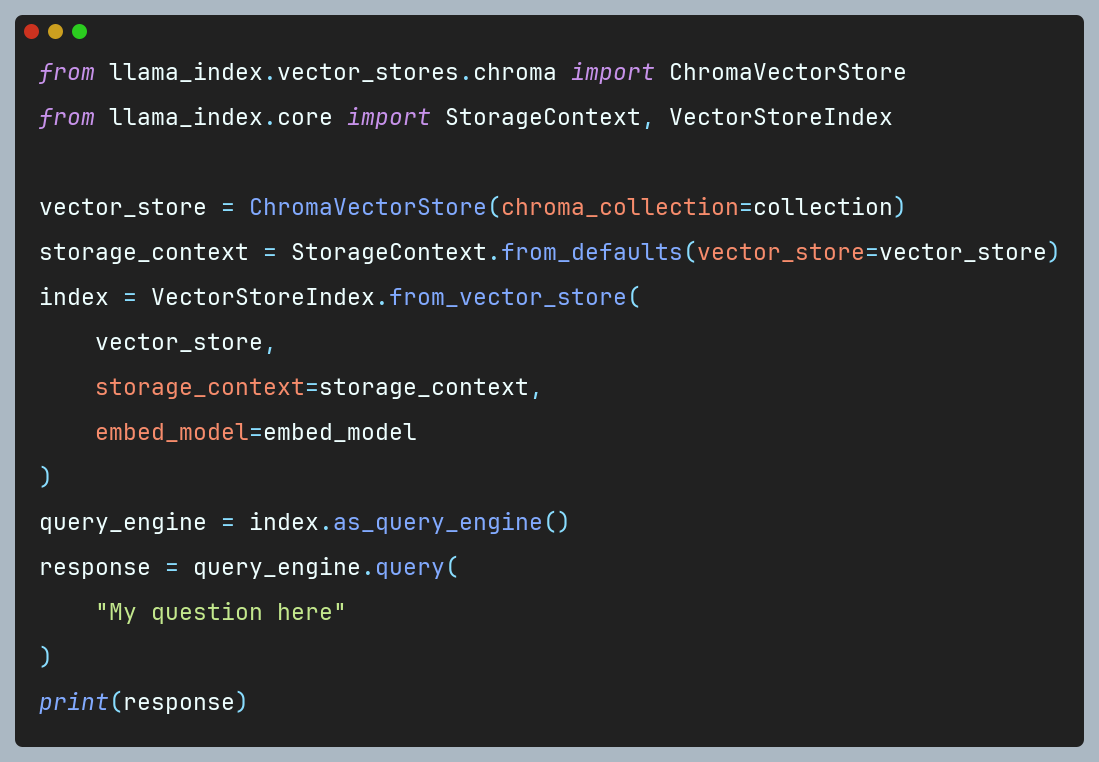
Utilizing a previously established collection, we construct an instance of the ChromaVectorStore class. Subsequently, it is imperative to instantiate a StorageContext object, serving as a toolkit container for storing nodes, indices, and vectors – a crucial component utilized in the subsequent step to create an Index. In the final phase, an Index is formed based on the vector storage and its context. Here ChromaVectorStore object is transformed to VectorStoreIndex using the from_vector_store() method, effectively making the ChromaVectorStore represent the same object type as VectorStoreIndex. Here, it is also crucial to specify the embed_model parameter with the same embedding model that was used to compute embeddings from chunks. Providing a different model or omitting it will result in dimensional errors during querying. Following the creation of the Index, analogous to the VectorStoreIndex class, we establish an engine to field inquiries regarding our documents.
Embedding search methods
In previous technical sections, we discussed how to index custom documents to query them using natural language through two libraries: the built-in tools offered by LlamaIndex and the integration of Chroma with LlamaIndex. However, it is worth mentioning how these frameworks search for similar embedding vectors. In a vector space, to compare two vectors, one must perform a comparison operation using a mathematical transformation (metric similarity). The most used metric is cosine similarity, which is the default metric used by LlamaIndex. Conversely, Chroma defaults to the Squared L2 metric but also provides cosine-similarity and inner product, allowing users to choose the most suitable metric. Unfortunately, at the time of writing this article, it is not possible to change the cosine similarity metric in LlamaIndex, as it is hardcoded. In contrast, Chroma allows for metric selection easily by specifying it in the metadata parameter when creating a collection:
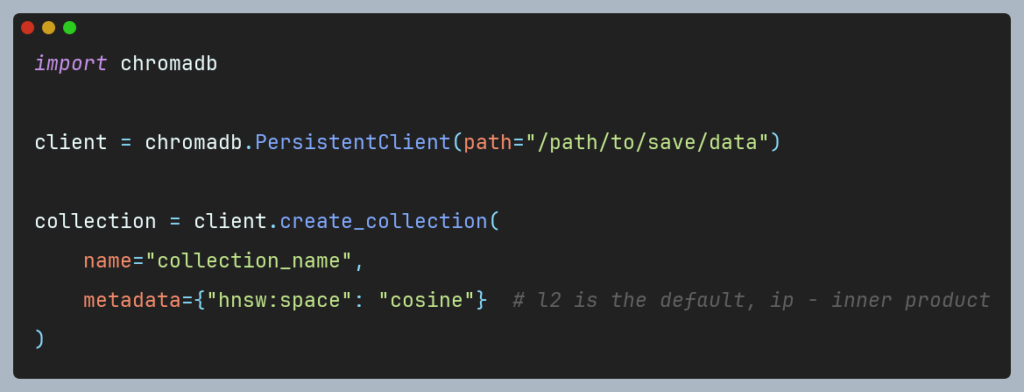
Each similarity metric has its advantages and disadvantages, and the selection of a specific one should be made based on the developer’s best judgment. Cosine similarity, while the most popular and commonly used with vector embeddings, has its limitations, and should be used cautiously. For a deeper understanding of the nuances and potential pitfalls of using this metric, please refer to a detailed discussion in this article.
Summary
LlamaIndex with VectorStoreIndex and external vector databases like Chroma are fundamental tools for creating Retrieval-Augmented Generation systems. Both frameworks have been implemented and evaluated in our internal project to ingest and store vector embeddings from various data sources.
Regarding costs, LlamaIndex requires an OpenAI API key to calculate vector embeddings, as it uses the OpenAI text-embedding-ada-002 model by default, which incurs charges for each calculation. In contrast, Chroma employs open source embedding models, eliminating this cost.
For simpler RAG systems, involving a limited number of documents, VectorStoreIndex is a robust and effective choice. However, in real-world applications, the number of documents can grow rapidly, making in-memory storage inefficient. The natural solution is to use an external vector database to store this data. Several tools on the market facilitate integration with such databases, including LlamaIndex, which continues to evolve and offer new functionalities for efficient RAG construction.
It is important to note that storing documents and vector embeddings is just part of the equation. Equally crucial are the methods for parsing documents, appropriate chunking, and capturing the nearest chunks. These elements play a significant role in the overall performance and efficiency of RAG systems.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.