
 +48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


The client
Santander Bank Polska, one of the biggest Polish banks with 10,000 employees and a part of a global group with 166 million customers, € 1,020 bn customer loans, € 1,800 bn total assets and € 1,184 bn customer deposits + mutual funds.
The client’s goal is to be the best open financial services platform, by responsible action and earning the meaningful trust of all stakeholders – people, customers, shareholders, and communities.
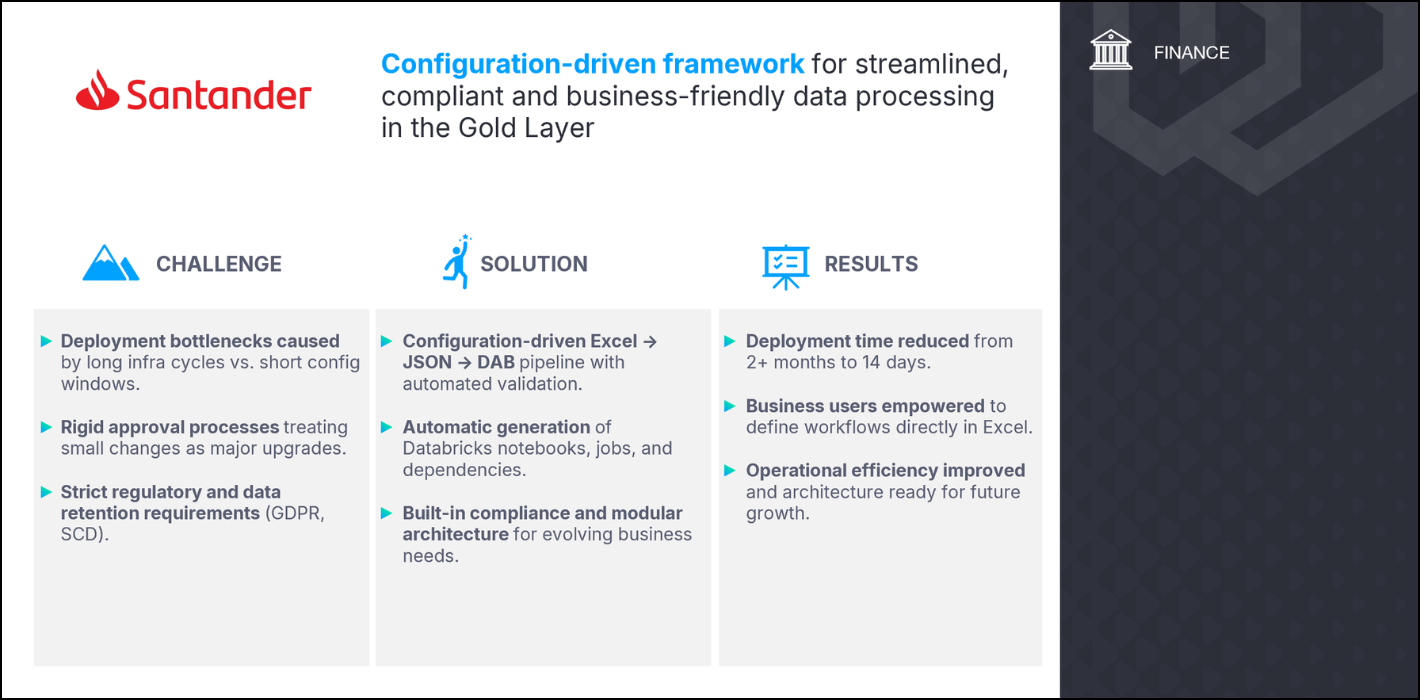
The challenge
Managing data pipelines on a large scale is rarely straightforward. Santander Bank Polska, like many large enterprises, faced the challenge of supporting rapidly evolving business needs while handling large and complex dataflows under strict regulatory and security requirements. Fragmented approaches and the absence of consistent standards across teams further complicated the situation. These conditions translated into a set of key challenges:
- Handling large-scale dataflows efficiently, ensuring high throughput, low latency, and reliable orchestration across multiple systems, while maintaining data quality and consistency.
- Critical deployment bottleneck, with long approval and release cycles for even minor changes, which made it difficult to react quickly to new requirements.
- Evolving business requirements, demanding modular and extensible architecture that could absorb adjustments on the fly while preserving overall stability and performance.
- Stringent regulatory and security standards, including GDPR compliance and banking-specific data protection rules, requiring a careful balance between protection and performance.
- Historical data management and SCD strategy implementation, involving complex handling of Slowly Changing Dimension types (SCD1, SCD2, SCD4) and automated data retention.
- Maintenance of multiple ETL tools and large numbers of processes, leading to operational overhead and inefficiency.
- Lack of standardization in data pipeline design, resulting in duplicated effort and inconsistent practices across teams.
- The need to empower business analysts to work with data without heavy reliance on engineering teams.
- Acceleration of development cycles through automation of deployment and configuration management.
The solution
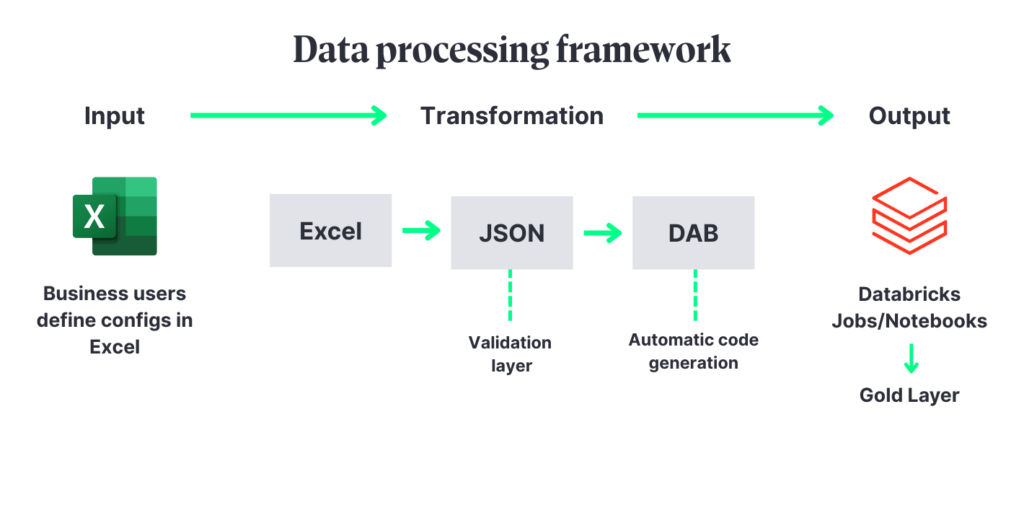
BitPeak designed a configuration-driven framework that revolutionised how Santander Bank Polska designs and deploys its data with an innovative Excel-to-JSON-to-DAB (Databricks Assets Bundle) pipeline. The system transforms business-defined Excel configurations into fully validated, production-ready Databricks workflows – streamlining what used to be long, code-heavy deployment cycles into rapid, configuration-based updates. Operating entirely within Santander’s secure Cloud infrastructure, it meets strict banking regulatory standards, including GDPR and internal data governance requirements.
Using Databricks Asset Bundles as the deployment backbone, the pipeline automatically translates configuration inputs into optimised notebooks, job definitions, and orchestration logic. Business users can define new processing requirements in a familiar Excel interface, while the framework handles the conversion and validation– reducing typical implementation windows from months to just two weeks. This approach allows Santander to adapt quickly to shifting business priorities without the overhead of manual infrastructure changes.
Core capabilities of the solution include:
Automated infrastructure generation
At the heart of the framework is a stable automation layer that creates all necessary Databricks infrastructure directly from validated Excel-based business definitions. Without touching the underlying codebase, users can introduce new data transformations, orchestrations, and dependencies. The system then produces ready-to-run pipelines, eliminating the need for lengthy infrastructure development cycles.
Modular architecture for evolving needs
A four-phase processing structure provides clear extension points for new logic – supporting custom joins, aggregations, save strategies, and both streaming and batch modes. Built-in validation ensures all configurations are technically correct before deployment, while template-driven notebook generation accommodates both standardised patterns and unique business rules.
Regulatory compliance and security
The framework handles banking regulatory requirements through built-in compliance features. Data masking functions protect sensitive information. The solution includes safety features like automated data retention policies for GDPR compliance and secure credential management through Azure Key Vault integration.
Advanced historical data handling
The framework automatically manages complex historical data scenarios, including current-state tracking (SCD1), complete history preservation (SCD2), and dual-table approaches (SCD4). Technical metadata is handled automatically, with efficient change detection and optimised storage strategies.
Empowering business users
The Excel interface brings complex data engineering capabilities to non-technical teams without compromising quality. Multi-level validation checks, a job scanner for monitoring data freshness, and automatic triggering of dependent processes allow users to design self-maintaining pipelines that perform reliably in production.
To reach our goal, we used the following tech stack:
Core Development:
- Python 3.11
- UV Package Manager – Modern dependency management and virtual environment handling, replacing traditional pip for faster package management
Databricks:
- Databricks Connect – Remote Spark session connectivity for local development and testing
- Databricks SDK – Workspace management, job orchestration and cluster operations
- Databricks Unity Catalog – Centralized data governance, access control and metadata management
- Delta Lake – ACID transactions, time travel capabilities and optimized storage for all data processing workflows
- Databricks Assets Bundle (DAB) – Infrastructure-as-code deployment and resource management
Data Processing:
- PySpark
- Spark SQL
- Pandas
Cloud Infrastructure:
- Microsoft Azure Data Lake Storage (ADLS) – Scalable data storage for intermediate and Gold layer data
- Azure Key Vault – Secure secrets management for database credentials, API keys, and sensitive configuration parameters
Benefits:
Management
The solution reduced deployment times from 2+ months to 14-day configuration windows, enabling management to respond faster to business needs. The unified approach to data management eliminates resource waste from duplicated efforts, while automated job orchestration and monitoring reduce operational overhead.
Strategy
Our framework enables the bank to achieve long-term cost optimization through centralized data management and efficient resource utilization, supporting growth initiatives. The solution’s flexibility and extensibility ensure it adapts to future business needs, providing a solid foundation for expanding analytical capabilities and supporting digital transformation objectives.
Business Users
By providing direct control over data processing workflows through a familiar Excel interface, the framework supports daily operations for business users. Business units can now independently modify data processing logic and adjust transformation rules. This operational independence resulted in faster decision-making cycles and improved productivity across data-driven business processes.







