+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


A field guide for Business Analysts, operators, and anyone who owns operational decisions – not just software.
This playbook is for operational decision-making systems: planners, optimizers, recommenders that change schedules, prices, routes, allocations, or approvals. It is not a treatise on every kind of AI. Treating these systems as “a planner searching legal moves inside a space you design” will save you months and prevent expensive failures.
Below are five lessons with concrete deliverables, mechanics, outside IT examples, and failure patterns. Use them as working templates.
1. Don’t write more rules – define the game
Rules try to predict the future. Good games set the boundaries and let players adapt inside them.
What you actually produce
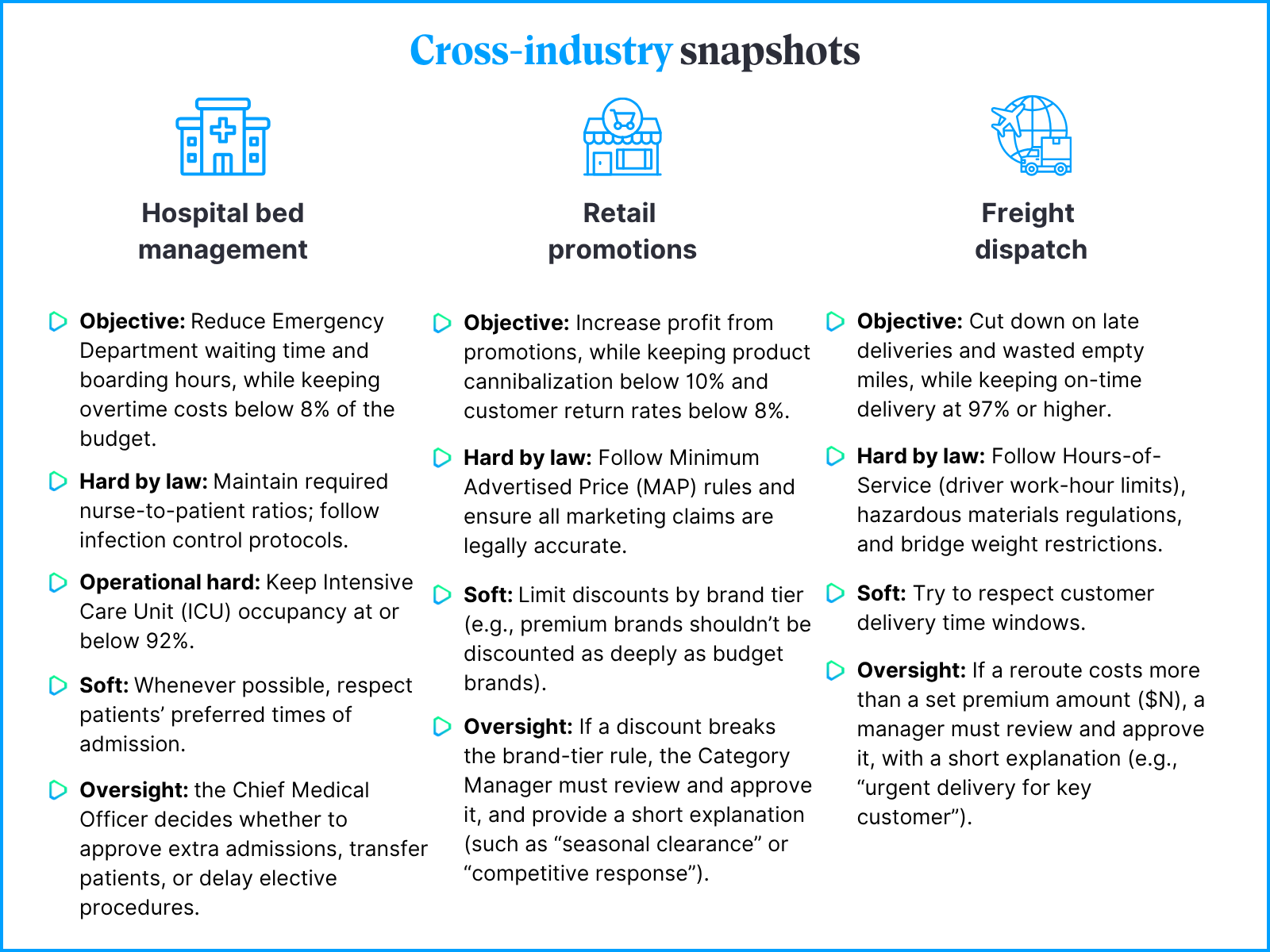
Objective function (with units & bounds): what the system maximizes or minimizes, with upper and lower limits that stop it from pushing the metric to extremes.
- Keep passenger delays as low as possible, but don’t spend more than $X per disruption event.
- Increase conversions, while making sure profit margins stay above 14% and product returns stay below 7%.
Constraint register (typed)
- Legal/ethical (HARD BY LAW): e.g. safety regulations, labour rules, lack of discrimination. Not tradable.
- Operational hard: physics, capacity, capital rules.
- Business soft: comfort, brand, preferences – crossable with explicit waiver.
Oversight bands: thresholds for auto, review, block, who signs, at which numbers, with an audit trail.
Mechanics
- Write the objective like a scorecard, not a slogan. Give units, a target band, and 2–3 guardrails.
- Type every constraint. Mark legal/ethical as HARD BY LAW, business soft as WAIVABLE, and link each to authority.
- Pre-decide escalation. “If plan crosses soft constraint X by >Y%, route to Z role with warning text.”
Failure patterns
- Mushy goals: “Improve efficiency” is a poster, not a plan.
- Everything “hard”: If you hard-lock preferences, you just rebuilt brittle rules.
- Blurry human role: Saying “human-in-the-loop” without stating when and for what is just pretending.
2. Your action space is your strategy
You can’t optimize what doesn’t exist. Enumerate legal moves, when each is allowed, and how it hits the score. Treat fairness/legal as gates, not prices.
What you actually produce
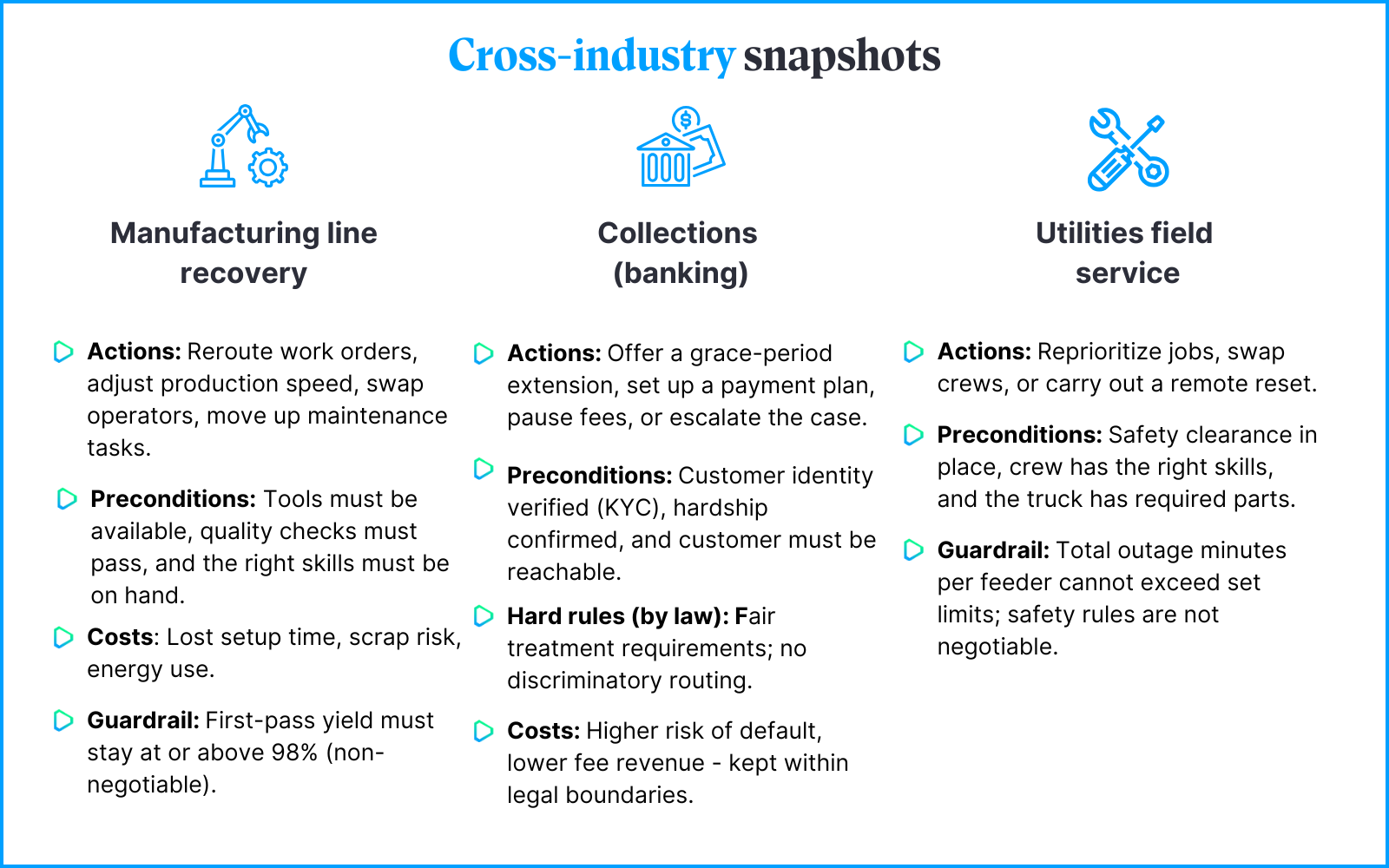
Action lexicon (verbs): The set of moves the system is allowed to make.
Preconditions: The facts that must be true before a move can happen (e.g., required skills, safety checks, available inventory, permits, capacity, compliance).
Cost & penalty model: How each move affects the goal, expressed in the same units as the objective (money, time, risk, etc.). Only include effects that can truly be traded off.
Guardrails for intangibles: where pricing is squishy (brand, long-term trust), use CAPS or scenario constraints instead of a hand-wavy penalty.
Mechanics
- Start broad, then narrow down. List all the possible moves at first, but cut out anything you can’t manage or measure early on.
- Tie every move to solid evidence. Link each precondition to a trusted data source.
Example: “Crew is legally allowed to fly” → checked against the rostering system and duty calculator. - Spell out the side effects. Show clearly how each move impacts things like penalties, extra truck trips, or energy use – but only if those impacts can really be traded off.
- Describe each move in 3 lines:
“Legal when…” (the conditions that must be true).
“Bound by…” (the hard rules that can’t be broken).
“Scored as…” (how it affects the objective, in numbers).
Failure patterns
- Unpriced tradables get abused: If “cancel order” is free in the model, it will be overused.
- Hidden preconditions kill plans: If you only discover the requirements when you try to execute, the plan fails.
- Fairness and legality aren’t negotiable: Don’t try to treat them as costs you can trade off – they are hard limits.
3. Data is a contract, not a rumor
Smart plans collapse if the inputs are outdated or incomplete. Treat data like a supply you can rely on: with clear owners, freshness guarantees, and backup rules when things go wrong. Don’t just show warnings – make the system change its behavior when data slips.
What you actually produce
Critical input list: For each key feed or table, write down the owner, schema, expected delay, and what level of missing values is acceptable.
Service-level objectives (SLOs): Start with SLOs for entire feeds (like “lag ≤ 5 minutes, ≥ 99% complete”). Only go to field-level SLOs for inputs that directly unlock or block actions.
Degradation plan: Define what happens when SLOs aren’t met: which actions are blocked, what banner appears in the UI, when the system should stop, and who gets notified.
Mechanics
- Connect actions to data. Map each precondition (from Lesson 2) to the data feed that proves it.
- Draw clear red lines. Example: If the aircraft maintenance feed is older than 30 minutes, block “swap aircraft” and show a “Data degraded – aircraft moves disabled” banner.
- Enforce the contract. Send alerts to data owners, display clear labels to users, and log issues for auditors.
- Keep it simple for operators. Combine all warnings into one visible “data health” banner instead of flooding them with multiple alerts.

Failure patterns
- Vague promises: “Near real-time” isn’t a measurable standard – write exact numbers.
- Warnings without action: A banner that doesn’t change system behavior is just decoration.
- Too many field-level SLOs: Monitoring every field creates noise and alert fatigue.
4. Clarity, ergonomics, and audit beat magic
People trust and adopt systems they can understand at a glance – and that don’t bury them in alerts.
What you actually produce
Display policy: decide what the operator sees, what is hidden, and what gets flagged.
- Plans that break hard rules never show in the main screen.
- They are still reviewable in a debug/admin view, with reasons, for diagnosis.
- Plans that stretch soft limits appear, but with clear flags and waiver text.
Reasoning artifacts
- Score against the objective (with units and guardrails).
- Constraint checklist: met, stretched, or blocked (typed).
- Rationale: “traded X for Y to keep Z within cap.”
Operator UX
- Approve; Request changes (“same SLA, lower spend”); What if.
- „What-ifs” can be asked in natural language, but the system should compile them into a structured form (with units, bounds, and which constraints may flex).
- Override reasons: Operators must log why they overruled a plan (safety, feasibility, cost, ethics). These patterns feed back into design.
- Alert hygiene: Cap the number of warnings, group related issues together, and avoid noisy repetition to reduce fatigue.
Mechanics
- Make the score obvious. Show it prominently and explain it in one line.
- Tie every flag to the constraint register. Show who approved a waiver and when.
- Structure what-if requests. Natural language is fine for input, but results must be tied to structured data.
- Log overrides with reasons. Review patterns regularly to improve the system.
Failure patterns
- Fake explainability: Long paragraphs without a score or checklist create distrust.
- Blurry accountability: If approvals don’t leave a trail, governance fails.
- Alert fatigue: Too many flags mean operators ignore all of them.
5. Demos don’t pay invoices – outcomes do
Keep user acceptance testing (UAT) for the UI and integration. But when it comes to proving value, judge success by real-world results and how people actually use the system – and always measure against a baseline.
What you actually produce
Measurement plan: Define a clean baseline, keep detailed decision logs, and add safeguards for seasonal or unexpected shocks.
3 levels of metrics
- Business outcomes: money saved or earned, time reduced, safety improved, emissions cut, customer experience gains – always measured in units.
- Decision quality: how well constraints are followed, how much rework is needed, distribution of plan scores, time it takes for approvals.
- Adoption & acceptance: who is using the system, how often they accept vs override plans, and the main reasons for overrides.
Rollout steps (with metrics for each stage)
- Shadow mode: compare system plans against human decisions; track latency and cost to operate.
- Human in the loop: measure acceptance rate, reasons for overrides, and time to decision.
- Limited autonomy: track guardrail violations (should be zero) and outcome improvements within confidence limits.
Mechanics
- Log the important stuff. Scores, flags, approvals, overrides (with reasons), and outcomes must all be recorded.
- Fix the economics before the model. If results stall, adjust objective weights, guardrails, or the way trade-offs are displayed – don’t jump straight to retraining.
- Always prove with a baseline. Use shadow testing, canary releases, or A/B experiments – not gut feel.
Failure patterns
- Demo driven victory laps: A slick-looking plan isn’t value if it doesn’t improve outcomes.
- No baseline: Without a counterfactual, “better” is just an opinion.
- Chasing model metrics. :Precision or AUC might look good, but they don’t pay the bills.
The punchline
Operational AI isn’t magic. It’s a planner searching legal moves inside a space you intentionally design: goal, constraints, oversight. Draft that space, price only what’s tradable, encode the rest as non-negotiable gates, and show the math to the people who live with the consequences. Do that, and your system will bend with reality instead of breaking on it.
Maxims to tape to your monitor
- If you can’t score it, you can’t manage it.
- If you can’t govern a move, you shouldn’t allow it.
- If data has no SLO, the plan has no spine.
- If the UI can’t show the trade-off, the operator won’t either.
- If the demo is the proof, there is no proof.
One consolidated Ship-It checklist
Objectives & Constraints
- Objective is written with clear units, a target range, and upper/lower limits.
- Constraint register separates: Hard by law, Operational hard, and Business soft.
- Oversight thresholds and approvers are named.
Actions & Preconditions
- Full list of allowed actions; each one has: Legal when… / Bound by… / Scored as….
- Preconditions are tied to reliable data sources.
- Intangibles (brand, trust, reputation) handled with hard limits, not vague penalties.
Data Contracts
- Feed-level SLOs (freshness, completeness) with owners; field-level SLOs only for gating inputs.
- Degradation policy: block risky actions and show one clear data health banner.
UX & Governance
- Main view hides plans that break hard rules; admin/debug view shows them with reasons.
- Score, constraint checklist, and rationale are always visible.
- “What-if” requests are compiled into structured queries.
- Overrides require a reason code; alerts are grouped and rate-limited.
Measurement & Rollout
- Baseline defined; shadow-mode metrics in place; HITL thresholds clear.
- Outcome, decision quality, and adoption metrics are tracked.
- Counterfactual testing (shadow runs, canaries, or A/Bs) is planned.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.