+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


Introduction
In today’s programming community, „vibe coding” has been everywhere. The term, popularized by Andrej Karpathy, has become a common way to deliver code. The continuous development of AI and, consequently, AI-powered IDEs has given developers a new way to approach software creation.
Instead of spending hours reading API documentation and following design patterns to deliver bug-free code, developers can now simply ask a model for what they want and then adjust the result to their needs. An AI IDE has become a coding partner that suggests solutions and adapts in real time. But how does this work under the hood? What enables an AI IDE to move beyond autocomplete and become a true coding partner?
In this article, we’ll break down the core architecture of Cursor AI, explore the mechanics of vibe coding, and show how these systems leverage modern language models, context management, and code analysis to create a radically different programming experience.
Context
In generative AI, „context” is the information a model uses to understand and respond appropriately to a given case. In practice, context can include the user’s previous messages, metadata such as location or time, and even external documents or data sources that guide the model’s reasoning. The richer and more relevant the context, the more accurate, coherent, and personalized the model’s responses will be.
Suppose we want to add new functionality to our project. It is not enough to just add a function that does the job. We also have to pay attention to the code that is already written and the existing dependencies between files and modules. The same goes for vibe coding: the IDE first has to understand the current codebase to properly add new portions of code to it. For this to be possible, context is needed. In other words, we need to feed the model with data so that it can generate code correctly.
By default, Cursor reads all files recursively in the workspace directory, except those defined in the .cursorignore file. This file works like .gitignore and should be used the same way, for example, to ignore files that contain credentials or API keys. However, due to the unpredictability of LLMs, complete protection is not guaranteed; keep this in mind.
Apart from security matters, ignoring files can also improve IDE performance. While working on a large codebase or a monorepo, we can exclude irrelevant files to enable faster indexing and more accurate file discovery.
Splitting Context
After filtering unwanted files, Cursor splits the code. Cursor does not publish detailed documentation about how this splitting process works internally. To better illustrate the concept, we can look at Claude Context, an open-source project from Anthropic’s community that demonstrates how code can be recursively parsed and split into smaller chunks using AST (Abstract Syntax Tree) techniques. In this case, Claude Context supports nine programming languages and serves as a useful reference point for understanding how an AI IDE might process code for context.
| Language | Node Types |
| JavaScript | function_declaration, arrow_function, class_declaration, method_definition, export_statement |
| TypeScript | function_declaration, arrow_function, class_declaration, method_definition, export_statement, interface_declaration, type_alias_declaration |
| Python | function_definition, class_definition, decorated_definition, async_function_definition |
| Java | method_declaration, class_declaration, interface_declaration, constructor_declaration |
| C/C++ | function_definition, class_specifier, namespace_definition, declaration |
| Go | function_declaration, method_declaration, type_declaration, var_declaration, const_declaration |
| Rust | function_item, impl_item, struct_item, enum_item, trait_item, mod_item |
| C# | method_declaration, class_declaration, interface_declaration, struct_declaration, enum_declaration |
| Scala | method_declaration, class_declaration, interface_declaration, constructor_declaration |
| SQL | SelectSqlStatement, InsertSqlStatement, UpdateSqlStatement |
Common node types across languages | Source: Claude-context
We can see that for different languages, parser distinguishes different Node Types. Node types are higher-level constructs that group tokens and other nodes into meaningful structures. Each node in an AST represents a syntactic construct in the source code. The node type describes what kind of construct it is. This way we can keep semantic meaning of our codebase, not only plain text.
For files written in languages that aren’t supported, the code is split using rule-based text splitters like LangChainCodeSplitter. They rely on regular expressions, indentation, and token heuristics to break code into chunks.
Embedding Stage
After splitting the codebase into chunks, Cursor begins embedding those smaller parts into vectors. Embedding vectors are numerical representations of data (words, images, or code) in a high-dimensional space where similar items are close together. In practice, embeddings allow machines to „understand” and compare complex data efficiently for search, classification, or recommendation tasks.
Rather than encoding individual tokens, Cursor embeds the entire context of a code fragment. Each vector thus represents a complete code chunk, allowing Cursor to better understand code context and relationships, and provide more accurate code completions and suggestions.
All codebases opened in Cursor are chunked and embedded using Cursor’s own embedding model.
Detecting Differences
Cursor indexes the codebase at initial setup and after each change. Instead of recomputing indexes for every file from scratch, it detects differences and updates only the affected data.
For this purpose, it uses a Merkle tree. A Merkle tree is a data structure in which each leaf node stores a hash of data (such as a file chunk), and parent nodes store hashes of their children, up to a single root hash. This structure makes it possible to quickly verify if any part of the data has changed, because a single file modification alters only the hashes along the path to the root.

Animation of a Merkle Tree | Source: Author’s own illustration
Storing and Querying
All indexed codebases must be stored somewhere, and Cursor provides a structured approach.
Cursor offers two privacy modes for storing data:
- Privacy: Your code and embeddings are kept private and accessible only to you.
- Shared: Data can be shared across your team or organization for collaborative work.
Regardless of the chosen privacy mode, data is stored in AWS S3 as the primary storage layer. However, simply storing the data is not enough to efficiently handle search and retrieval across multiple users and codebases. To enable fast and accurate code search, Cursor leverages a search engine provided by Turbopuffer.
Turbopuffer is a specialized search engine designed for high-dimensional vector data. It indexes embeddings stored in S3 and uses similarity search algorithms to quickly find the most relevant code chunks based on context. By focusing on vector similarity rather than exact matches, it allows Cursor to retrieve semantically related code fragments, even if the exact code hasn’t appeared before.
This makes Turbopuffer a perfect tool for Cursor, as it enables real-time, context-aware code suggestions and completions across large codebases while keeping the system scalable and efficient.
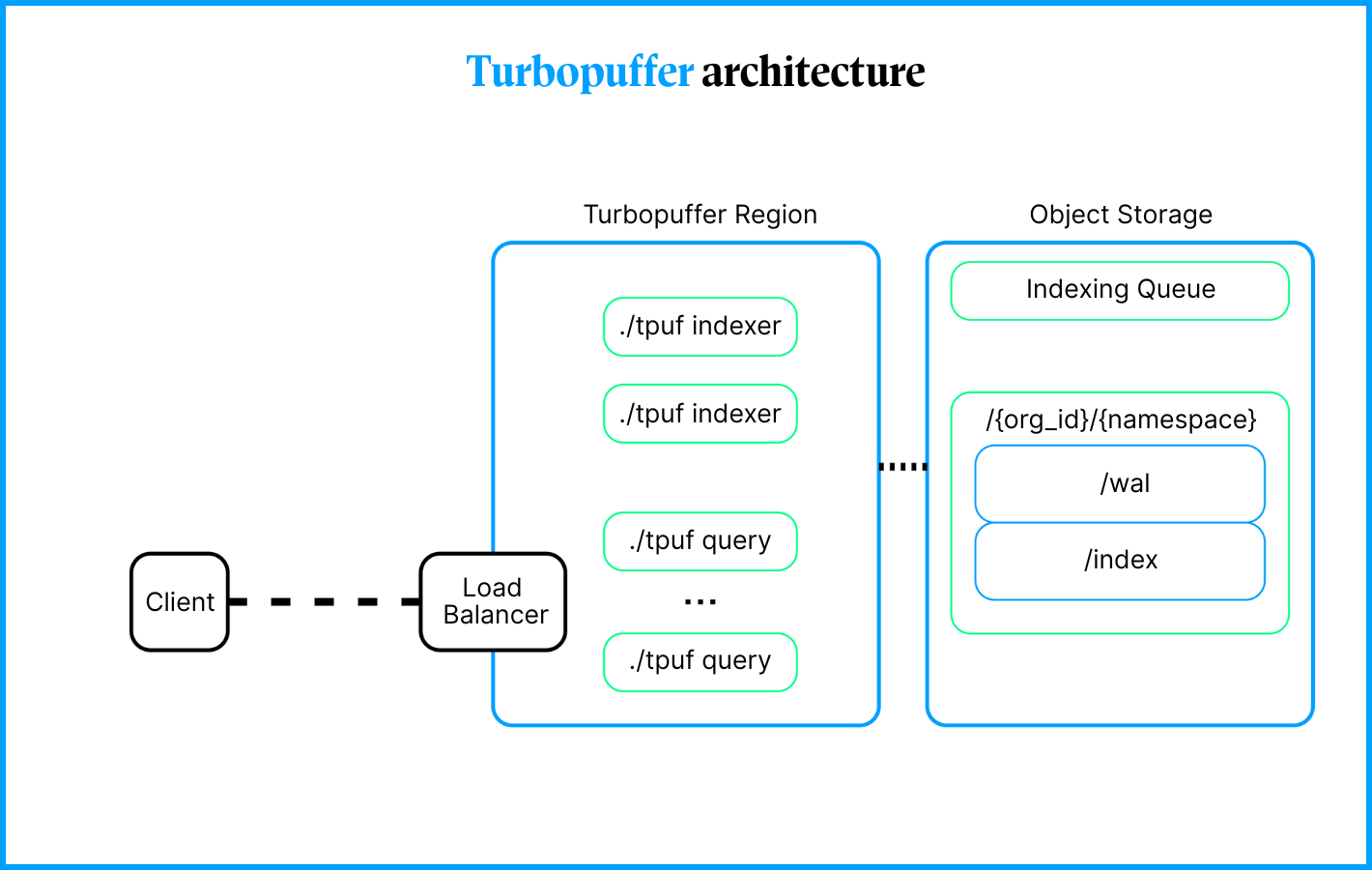
Turbopuffer architecture | Source Architecture
Each embedded codebase from every user is stored as a separate namespace in Turbopuffer. This helps keep different projects isolated from each other. Embeddings from one project are stored in their own namespace, and new embeddings are generated only within that specific namespace.
Turbopuffer also provides mechanisms like copy_from_namespace to recycle embedding vectors between namespaces. This offers a faster and more cost-effective alternative to re-upserting documents for backups or for namespaces that share documents.
Codebase indexing works as follows: when enabled, Cursor scans the opened folder and computes a Merkle tree of hashes for all files. Files and subdirectories specified in .gitignore or .cursorignore are ignored. The Merkle tree is then synced to the server. Every few minutes, Cursor checks for hash mismatches and uses the Merkle tree to identify which files have changed, uploading only the modified files.
On the server, files are first chunked and embedded, and the resulting embeddings are stored in Turbopuffer. To enable filtering of vector search results by file path, each vector is stored along with an obfuscated relative file path and the line range corresponding to the chunk. Additionally, embeddings are cached in AWS and indexed by the hash of the chunk, ensuring that re-indexing the same codebase is much faster.
During inference, a new embedding is computed and Turbopuffer performs a nearest-neighbor search. The server returns the obfuscated file path and line range to the client, which reads the corresponding file chunks locally. These chunks are then sent back to the server to answer the user’s query. This design ensures that, in privacy mode, no plaintext code is ever stored on the servers or in Turbopuffer.
Output Generation
Once the relevant code chunks are retrieved from the codebase, Cursor uses AI models to generate output tailored to the developer’s current context. This process happens in real time and supports multiple interaction modes, depending on how you want to work with the IDE.
Interaction Modes
Inline Mode: Cursor displays suggestions directly inside the editor as you type. These suggestions can be single-line completions or multi-line snippets. You can accept a suggestion with Tab, edit it in place, or dismiss it with Escape. Inline Mode is optimized for low-latency responses and uses a compact model when only a few tokens of context are needed.
Tab Mode is a specialized autocompletion system that optimizes for multi-line and cross-file edits. It tracks which suggestions you accept or reject; this feedback loop refines future recommendations. Tab Mode can add missing imports, run quick lint checks, and propose coordinated edits spanning files.
Chat Mode offers a multi-turn conversational interface to the codebase. Unlike inline suggestions, the chat can request clarifying details, propose alternative implementations, and produce patch diffs you can preview. It’s useful for code reviews, design discussions, or complex transformations that benefit from clarification.
Background Agents are autonomous processes that run tasks, test runners, linters, dependency updaters, or security scanners. They can create draft PRs, propose fix suggestions, run unit tests on changed files, and notify you of regressions. Agents should be permissioned and configurable (frequency, scope, privacy mode) to avoid noisy automation.
Model Zoo
Under the hood, Cursor uses modern LLMs from AI providers. We can choose from the newest models that are available

Some of Cursor’s available models | Source: Cursor Docs
Today’s leading AI models for coding, high responsiveness, and deep code understanding. Claude 4.1 Opus offers advanced reasoning and structured analysis for complex, multi-file edits, while Claude 4.5 Sonnet balances speed, accuracy, and extended context for everyday development. Gemini 2.5 Pro brings Google’s multimodal intelligence to code, integrating text, documentation, and project context seamlessly. OpenAI’s GPT-5 delivers state-of-the-art reasoning across massive contexts, with GPT-5 Fast optimized for low-latency, continuous IDE interactions, and GPT-5-Codex fine-tuned specifically for code generation and refactoring. Finally, Grok Code focuses on semantic precision and code-specific logic, rounding out a new generation of models designed to act as true collaborative partners in modern software creation.
Choosing Models
While working with our IDE, we can select specifically which model should be responsible for generating code and there are many ways, apart from choosing model which deliver best quality code we can focus on different parameters like speed, size of context, etc. Here is a simple diagram delivered by the Cursor team on how we should choose model for generating our code.
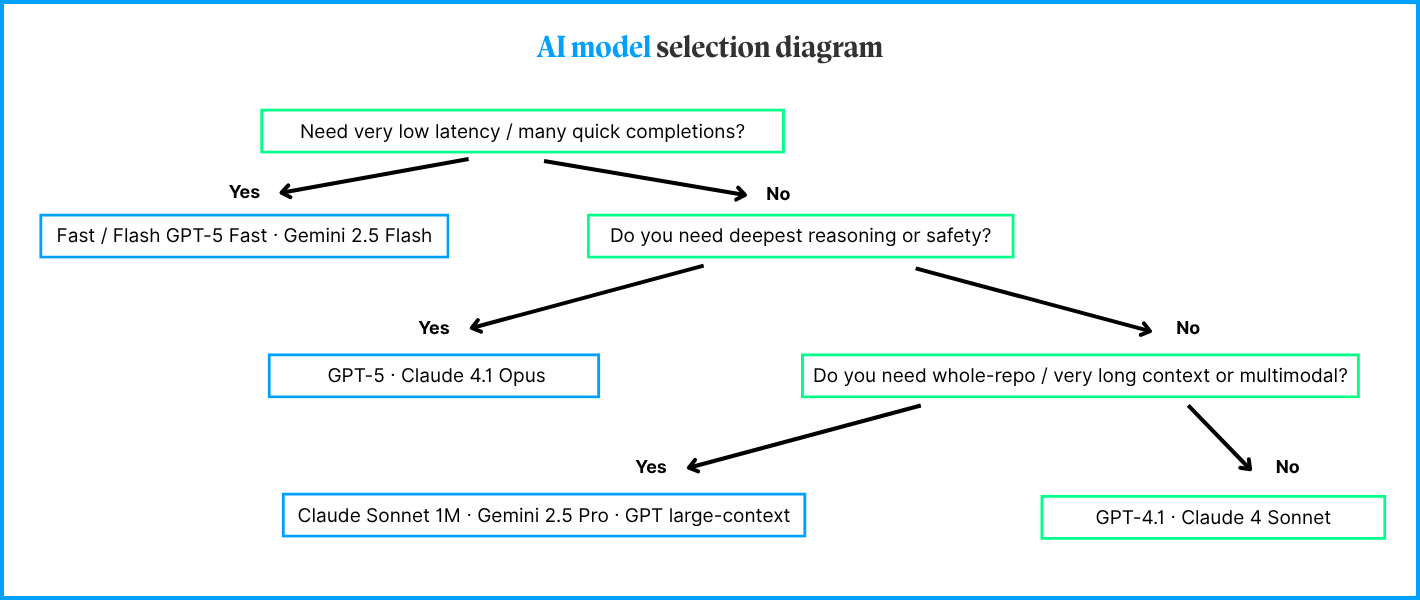
AI model selection diagram | Source: Inspired by Eric Zakariasson (X), redrawn by the author
However, if you don’t want to worry about choosing correct model for your task you can enable auto mode.
Enabling “Auto” allows Cursor to select the premium model best fit for the immediate task and with the highest reliability based on current demand. This feature can detect degraded output performance and automatically switch models to resolve it.
Improving Cursor Performance
When Cursor builds a project index, it scans your workspace, chunks files, computes hashes and embeddings, and stores those embeddings in a vector store (Turbopuffer). Large or noisy workspaces add latency, waste embedding budget, and reduce suggestion quality because the model is given irrelevant context. You can improve both speed and relevance by defining what to omit while indexing.
In case of a big monorepo Cursor won’t be even able to index it automatically, even though the option to index new folders is enabled, as it only works with folders with fewer than 50,000 files.
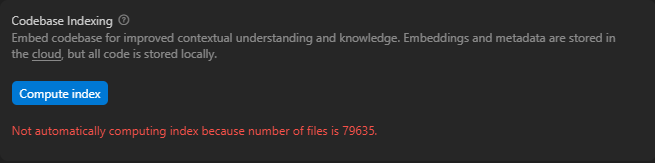
Indexing & Docs | Source: Cursor App
When working on a specific module or feature, understanding how Cursor handles context and embeddings lets you deliberately tune what the AI “sees.” Instead of indexing the entire monorepo every time, you can use the .cursorignore file to exclude independent or irrelevant modules, packages that your current component doesn’t depend on.
This selective indexing strategy speeds up performance, reduces noise in code suggestions, and ensures the AI’s context retrieval focuses only on the parts of the codebase you’re actively modifying.
For testing purposes, I used vsavkin/large-monorepo, which contains more than 79,000 files and was created specifically for benchmarking purposes. I tested this repository for indexing the codebase and for generating an answer that summarizes one of the given modules. Here are the results:
| Metric | Full Codebase | Single module |
| Files indexed | ~79 600 | ~15 000 |
| Indexing duration | ~38 min | ~6,5 min |
| Prompt response time | ~55s | ~30s |
| Context window usage | 7,3% | 5,1% |
Indexing performance benchmark | Source: Author’s own test
Clearly, we can see that indexing the whole codebase takes much more time than just the selected module; to be precise the computation time is roughly proportional to the number of files. However, the differences between the prompt response time and the context used are not so big. It might mean that Cursor intelligently prioritizes relevant parts of the codebase rather than brute-forcing through all indexed files.
Either way, it’s a good thing to know the codebase we are working with, for we can always save time while using our AI IDE.
Conclusion
As AI-powered IDEs evolve, understanding what happens beneath the surface helps you to work smarter. Tools like Cursor represent a shift from writing code line by line to collaborating with an intelligent system that understands structure, context, and intent. By learning how context, embeddings, and indexing work, developers gain control over what their AI partner focuses on improving both speed and precision. Whether it’s optimizing indexing with .cursorignore, leveraging background agents, or selecting the right model for the task, mastering these mechanics turns “vibe coding” from a buzzword into a practical, everyday advantage.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.