+48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com



In most migration programs I have been involved in, Databricks does not appear as a new gadget, but as an answer to a platform that has stopped scaling or become too hard to operate. The conversation about migration on a new platform usually starts with a growing sense that the current one is no longer keeping up. Teams spend more time on maintenance than on innovation, and simple changes begin to take disproportionate effort.
Working with teams facing these challenges is what inspired me to write this article. This text is intended for people who approve such decisions from the technical side: Principal Data Architects, Data Platform Managers, and BI / Data Engineering tech leads. Based on patterns I have seen across multiple migration programs, I decided to structure it as a concise, experience‑based checklist to help assess if and how moving to Databricks makes sense as a strategic data platform rather than a one‑off analytical environment.
It is also an introductory article in a series. All aspects mentioned here, from high level design, decision drivers and risk management to cost structure, governance and migration planning, will be developed in more detail in subsequent parts.
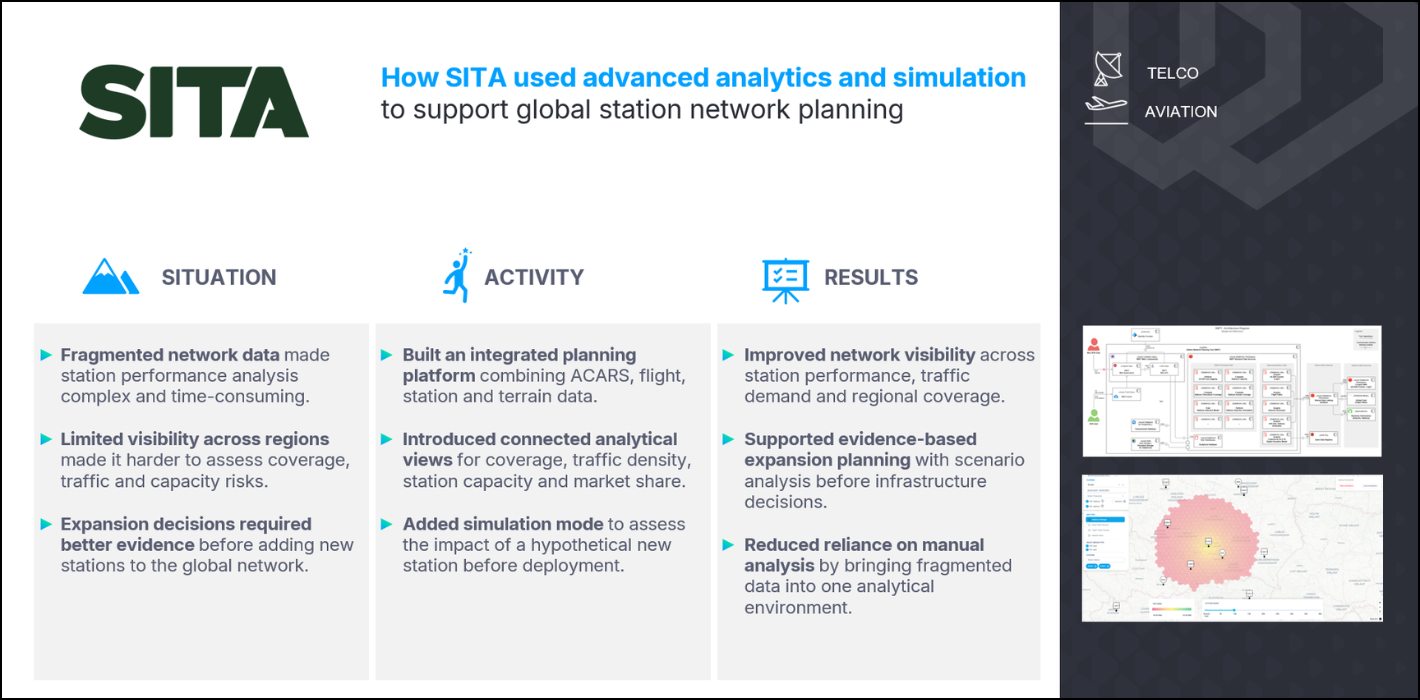
When a migration to Databricks really makes sense
In practice, migration tends to make sense when the existing environment is insufficient to meet constantly evolving requirements and expectations. Typical signs include:
- Fragmented architecture spread across many workspaces and projects
- Lack of a single, trusted source of truth for core domains
- Deployments and changes that are dependent on manual work
- Costs and performance that are difficult to explain or defend outside the immediate team.
In such situations, Databricks typically plays three roles simultaneously: it enables consolidation of scattered data solutions into a single lakehouse model, standardization of pipelines and environments across teams, and replacement of local workarounds with an explicit architecture and governance model.
If the current platform is still small, coherent, and under control, targeted clean‑up is often more effective than a full migration. Databricks delivers the most value when requirements and data assets are constantly evolving, providing a single platform with capabilities for improved performance, orchestration, governance, monitoring, and more, while reducing costs and time-to-value for new data initiatives.
Typical decision drivers
In real projects, the decision to migrate rarely results from a single factor. It is usually driven by a combination of pressures that reinforce one another.
Regulatory and compliance expectations are often the first driver that appears in formal documents. For example, airlines, banks or telecoms must prove where data is stored, how it is encrypted, who accessed it, and when. Ad‑hoc clusters and local databases make it difficult to demonstrate consistent controls, while a Databricks and Unity Catalog‑based platform can centralize policies, logging and audit.
The second group of drivers relates to the lack of a unified data governance model. Over time, separate teams build their own conventions for naming, quality checks, access management and documentation. This leads to parallel versions of core concepts such as customer, booking or payment. Databricks migration then becomes a chance to introduce a single Unity catalog that defines shared domains and clearly owned products.
A third driver is the set of technical constraints caused by complexity and accumulated debt. Pipelines created over many years, in several technologies and tools, are difficult to evolve further. New use cases – for example, operational dashboards combining punctuality, crew planning and ticketing – require joining data from systems that were never designed to work together. Databricks lakehouse model and standardized medalion architecture transformation patterns reduce the friction of adding new data products. ZeroBus with Autoloader and Lakeflow Connect are minimizing time and effort of data ingestion to a new platform.
The fourth driver is a growing network of dependencies between domains and systems that makes local change risky. One feed from reservations may be used by revenue management, loyalty, finance and operations. A change for one stakeholder immediately affects several others. A structured Databricks‑based platform allows the organization to formalize such shared objects and isolate downstream consumers through stable, governed contracts. It is achieved by leveraging Unity Catalog for data access, metric views and ensuring Data Quality with Lakeflow Declarative Pipelines.
Finally, management pressure for clear and explainable cost control is increasing. Without tagging, shared standards and a common platform, spending is spread across many line items and hard to attribute. Adopting FinOps‑aligned practices on Databricks – such as cost allocation by domain, environment and product – becomes itself a reason to consolidate.
Decision‑making becomes more constructive when teams move away from abstract feature lists and instead describe these concrete constraints of the current platform and the intended governance model of the target one, using them as explicit decision criteria.
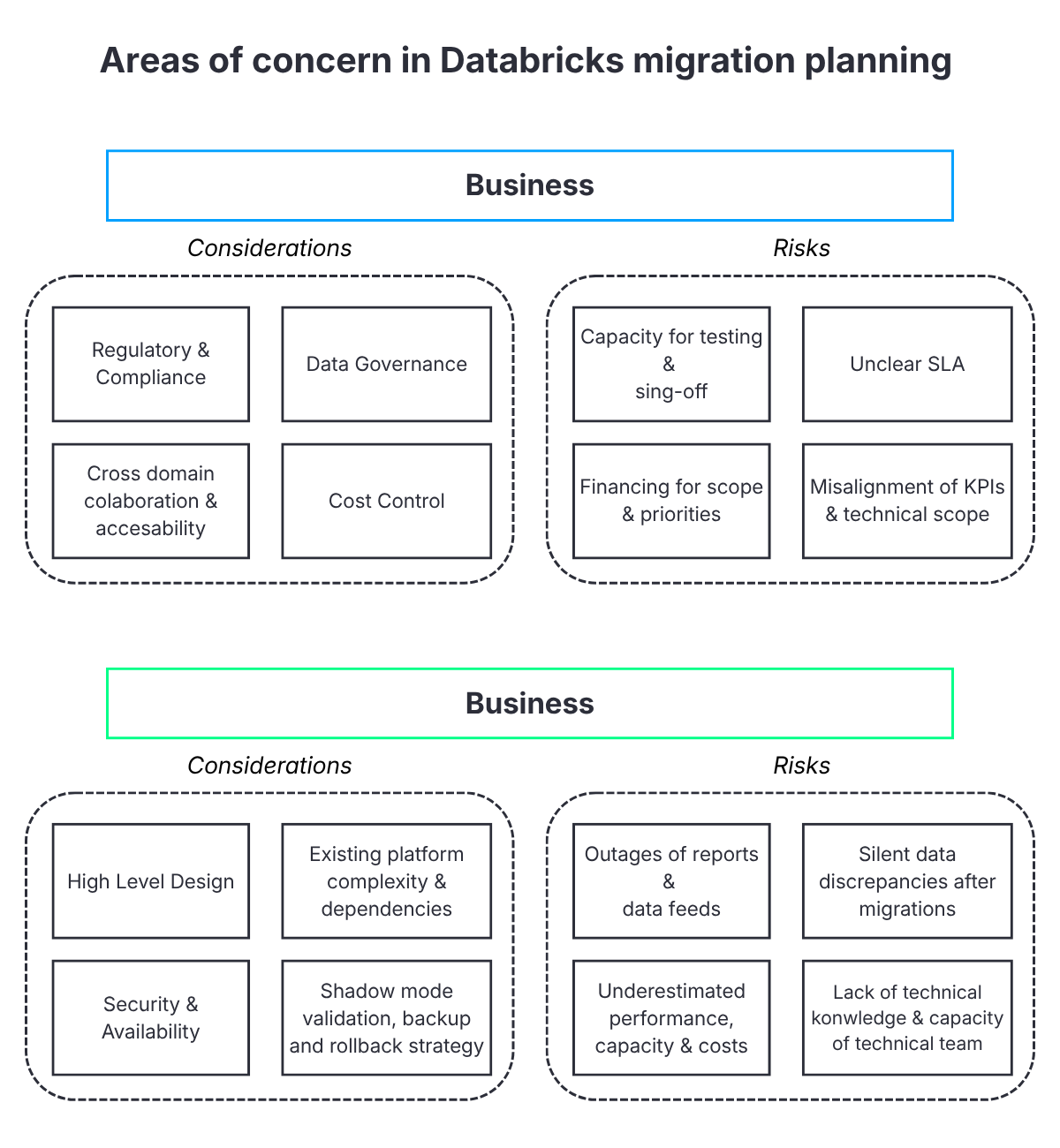
Risks that can be anticipated
Migration like any process, is exposed to some risks. Organization must be prepared for scenarios where some of them might occur. Inability to mitigate them can lead to severe costs, or in worst scenario stopping and rollback of migration. Across organizations and sectors, the same risk families recur and can be grouped into technical, organizational and financial dimensions.
On the technical side, the most damaging issues are report and data feed outages, silent changes in numbers after migration, and underestimated performance requirements. Typical examples include operational dashboards that suddenly lag behind reality during peak travel periods or revenue reports where totals change because of subtle differences in aggregation, rounding or filtering logic. Without a shadow mode, data comparison and clear acceptance criteria, such discrepancies only surface when business users raise incidents.
On the organizational side, the main risks are limited capacity across IT and business, and gaps in Databricks and lakehouse skills. Data engineering teams often maintain the legacy platform while also being asked to design and build the new one. Business teams are expected to test, sign off and sometimes redefine KPIs in addition to regular responsibilities. If new practices such as Terraform‑based infrastructure, GitOps, Databricks Asset Bundles or FinOps are introduced during the migration itself, teams effectively have to learn and deliver at the same time.
Financially, programs struggle when they ignore the cost of running multiple solutions in parallel during migration phases, allow scope to grow unchecked, or overlook operational costs for monitoring, security, and support.
For instance, for several months, there may be a need to maintain both the legacy data warehouse that feeds existing regulatory and financial reporting and the new Databricks‑based platform that supports pilots and new analytics use cases. Without explicit budget and time‑boxing for this shadow mode run period, the project can consume far more resources than initially assumed.
Migrations that handle risk well do not avoid problems altogether. They identify these risk families explicitly, attach owners, mitigation actions and decision thresholds to them, and agree on which risk levels are acceptable under what conditions.
What the organization really pays for
When migration costs are decomposed in workshops, they consistently fall into three categories. Each of them comprising several concrete items.
The first category is the migration project itself – analysis, design, planning and implementation are taking time and human resources. It includes analysis and inventory of existing jobs, tables, integrations and reports, as well as the design of a target architecture covering diagrams, naming conventions, environment models, security and governance. Considering the build‑out of landing zones, workspaces, and Unity Catalog as well as the implementation and testing of migration waves. In practice, this also includes tasks such as building dependency graphs, consolidating overlapping data flows and defining shared domain models.
The second category is the target platform in steady state. Here the organization pays not only for Databricks computing and storage, but also for the networks, security components and external services that support the platform. Typical elements include virtual networks and private endpoints, Key Vault and secret rotation processes, container and package registries, monitoring and log analytics workspaces, CI/CD infrastructure and licences for supporting tools. These costs do not disappear after cutover and must fit into a long‑term financial model.
The third category is organizational cost. This encompasses time for training and mentoring on new practices such as Lakehouse modelling, Git‑based development, infrastructure as code, FinOps and data governance. It also includes the time business stakeholders spend on testing, comparing old and new reports, accepting deviations and definition changes, and communicating with their own stakeholders. In regulated environments, additional effort is required to update procedures, documentation and audit trails.
Underestimating the third category is a frequent reason why migrations that look well‑founded in spreadsheets stall when executed, because the people who need to provide decisions, tests and approvals simply do not have the planned capacity.
Questions that should be answered explicitly
Before the start of a serious migration, successful implementations tend to insist on short, written answers to a set of core questions:
- What concrete business goals the migration is intended to support and how technical success will be measured
- Which systems and domains are truly critical and what continuity of operation means for each of them
- Whether dependencies between processes and data are understood to a level that allows for phased migration
- Can IT and business teams realistically commit alongside day‑to‑day work or should the migration effort be outsourced.
- What hard constraints apply in terms of time, regulation, contracts and risk
- Whether a formal rollback strategy is defined for critical areas, including data backup and retention policies, shadow mode duration, validation procedures, and clear technical steps for returning to the previous platform state if acceptance criteria are not met
If most answers are still under discussion, the design phase needs to be extended rather than the questions narrowed.
Red flags that justify a pause
In practice, migration programes rarely fails suddenly. They tend to show early signals that teams ignore until they start impacting delivery. Across different organizations, several warning signs repeat themselves:
- Migration scope defined as a broad, waterfall‑style rebuild with no clear prioritization
- Absence of an accountable business sponsor
- Lack of agreement on the target architecture or governance model
- No basic visibility into current and expected platform costs
When more than one of these conditions exists, migration initiatives frequently slow down sharply or fail outright. A deliberate pause to clarify scope, sponsorship, and architecture is almost always cheaper than pushing forward and restarting later.
A decision sequence that works better
The migration programs that deliver visible value tend to follow a structured decision sequence. In practice, the difference rarely lies in tools or architecture, but in how early teams align priorities, constraints, and decision criteria before implementation begins.
- A short, honest readiness assessment covering both technical and organizational aspects
- A high‑level business case with explicit benefits, costs, main risks and target architecture
- Joint workshops with key IT and business stakeholders to align priorities and constraints
- A decision between a focused pilot and a broader migration, with clear criteria for progressing to the next phase, clear definition of migration phases and plan
- Deciding on governance, access and operational model – domain owners and data stewards
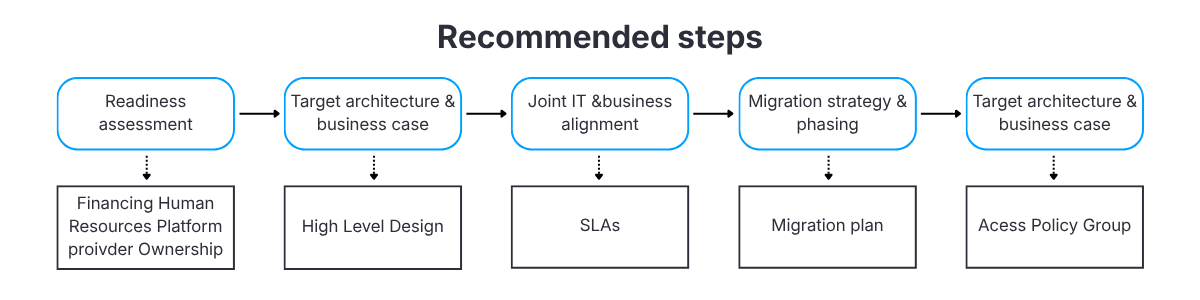
Skipping the initial steps usually leads to doing the same work later under pressure from delays, incidents, or budget constraints.
Minimum preparation before the project team starts
Programs start more smoothly when several basics are in place before the implementation team begins work:
- A decision‑making group with a sponsor holding a clear mandate
- An agreed access model for the project and a predefined list of required accesses
- A list of systems and reports that must remain available, together with their technical requirements
- A simple, explicit project governance model that defines who decides what and by which process
With these elements prepared, implementation work can focus on engineering tasks rather than on repeatedly renegotiating fundamental assumptions. Subsequent articles in this series will go deeper into practical patterns for governance, access models, and definition of critical systems.
Key takeaways and next topics in the series
Across migration programes, the difference between success and prolonged execution rarely comes down to technology alone. It is usually determined much earlier, by the level of clarity around key decisions. The decision to migrate to Databricks ultimately comes down to clarity in three areas:
- Understanding of the current environment and of the target state at a sufficient level of detail
- Realistic assessment of the organization’s ability to execute the migration
- A concrete plan for handling problems when they occur, including shadow mode and rollback options where needed
When these aspects are explicitly described and documented, a Databricks migration becomes a controlled engineering initiative rather than an experiment conducted on a production data platform.
In the next article, I will discuss further High Level Design (HLD) preparation and the impact of these decisions on target architecture and key business aspects such as compliance or regulatory requirements.
***
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Visualization, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.