
 +48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com



Schema hints are one of those Databricks features that rarely get mentioned in beginner tutorials, yet in practice turn out to be one of the most important tools you’ll reach for when building a reliable ingestion pipeline. The feature has been available in Auto Loader since its introduction as part of Databricks Runtime, and while the documentation does cover it, most users only discover it after schema inference fails for them for the first time.
Long story short, schema hints let you tell Spark: „treat this specific column as this specific type.” Everything else gets inferred automatically, so you’re still not forced to define the entire schema by hand. It sounds like a simple feature, and it is but in practice it lets you eliminate entire most of the problems before they ever reach the surface.
When does schema inference fail in a data ingestion scenario?
Let’s imagine a pipeline that reads application logs in JSON format from Azure Data Lake Storage via Auto Loader. Data flows smoothly until we discover that the user_id field, later used in a join with a customer table, lands in your Delta table as a STRING instead of BIGINT. A similar issue was raised by a colleague of mine not long ago. The transaction_sum_amount field, which should have been inferred as DOUBLE, showed up in the target table as STRING. A few minutes of debugging together was enough to identify the reason: somewhere in the logs, the transaction_sum_amount field contained an invalid input – the string „N/A”.
Typically, before we stumble upon schema hints, we consider solving this kind of problem in one of two ways:
Defining the full schema manually – we create a StructType with every column and pass it to the reader. It works, but:
- for wide tables with more than 50 columns, this becomes a tedious process
- every new column added at the source requires a code change
- across many pipelines with frequent source-side changes, maintenance quickly becomes a serious challenge
Post-read transformation – we read everything as STRING, then cast each field to its target type. Also works, but:
- the transformation code becomes harder to manage and stops being generic
- cast() failures are silent – if a cast fails, we get NULL value with no warning
Both approaches share the same fundamental trade-off: we become overly explicit either through a full manual schema you have to maintain, or through a layer of casting logic and in doing so you sacrifice the flexibility that schema inference was meant to give us. Schema hints offer a third path: precision, but only where we need it because inference falls short.
Schema hints in Auto Loader with cloudFiles
Schema inference in Spark is based on sampling. Spark analyzes the first 50 GB or 1000 files and deduces column types from that sample. The problem is that the sample can be unrepresentative – especially with JSON files, where the sample may contain only small values in the user_id field that fit within an INT range, while subsequent batches of files bring values that exceed it.
Schema hints work as an overriding directive: „regardless of what you infer from the sample, treat the user_id column as BIGINT.” Spark applies the hint before writing to schema location, which means it also gets persisted to the stored schema used in subsequent runs.
The key characteristics of schema hints are:
- Selectivity – you define types only for the columns you care about. Everything else is inferred as usual.
- Priority over inference – a hint always takes precedence over what Spark would deduce from the data.
- Compatibility with schema evolution – hints work alongside “schemaEvolutionMode”. We can enforce types on specific columns while still allowing new columns to be added automatically.
So how do schema hints compare to the approaches we discussed earlier?
| Defining full schema | Post-read transformation | Schema hints | |
| Effort | High | Medium | Low |
| Resilience to new columns | Low (error) | High | High |
| Type control | Full | Full | Targeted |
| Maintenance | Costly | Costly | Cheap |
Schema hints can be enabled using the „cloudFiles.schemaHints” reader option, and are available in all Databricks runtimes that support Auto Loader (Databricks Runtime 8.2+). Hints are passed as a comma-separated list of column_name and type pairs.

A practical end-to-end example
Let’s walk through a complete Auto Loader setup using “cloudFiles” to stream JSON files.
Assume a scenario where a mobile application sends events in JSON format. A simplified example payload looks like this:
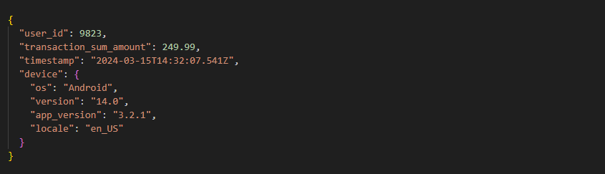
The problem is that “user_id” which can exceed the INT range was inferred as INT after Spark sampled the first 1000 files, and “transaction_sum_amount” was inferred as STRING due to some corrupted input data.
Let’s fix both issues using schema hints:
![from pyspark.sql.functions import col, to_json
# Constants configuration
SCHEMA_LOCATION = "<path_to_schema>"
CHECKPOINT_LOCATION = "<path_to_checkpoint>"
SOURCE_PATH = "<path_to_files_location>"
TARGET_TABLE = "bronze.target_table"
# Hints definition - transaction_sum_amount could contain floating-point numbers, user_id range exceeds INT
SCHEMA_HINTS = ", ".join([
"transaction_sum_amount DOUBLE",
"user_id BIGINT",
])
df_raw = (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", SCHEMA_LOCATION)
.option("cloudFiles.schemaEvolutionMode", "# add new columns to schema")
.option("cloudFiles.schemaHints", SCHEMA_HINTS)
.load(SOURCE_PATH)
)
# Optional transformations before save
df_transformed = df_raw.withColumn(
"device", to_json(col("device")) # nested JSON to STRING column
)
# Save to delta table
(
df_transformed.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", CHECKPOINT_LOCATION)
.option("mergeSchema", "true")
.toTable(TARGET_TABLE)
)](https://bitpeak.com/wp-content/uploads/2026/05/Schema-hints-3.png)
Best practices
Schema hints are simple to use, but also easy to misuse. The following practices should come in handy for getting the most out of them.
Apply schema hints only where inference falls short. Declaring hints for every column is against the whole purpose of this feature. Overusing hints makes our pipelines harder to maintain and hides schema changes at the source that we actually want to be visible.
Comment each hint or set of related hints explaining why we need it. By “comment” I don’t mean a general note along the lines of „why we use hints”, but rather a specific explanation of why exactly this particular hint or set of hints is necessary in our case. It may sound trivial, but trust me, it really speeds up maintenance work and makes handing off the codebase to colleagues easier. They’ll thank you for it.
Version hints alongside the pipeline code. If the source schema changes, the hints should change with it. Passing them manually through job parameters is not the best idea as it leads to drift between our code and configuration. Treating hints as code rather than config and storing them in the repository gives a few advantages. That way, every change is tracked, reviewable, and can be rolled back easily if something goes wrong.
Test on sample data before deploying to production. Before going live, verify that our hints behave as expected on a representative data sample. A high null count in a hinted column could be a signal that something may not be working as intended.
Monitor null counts after deployment. The simplest and most effective way to detect that the source format has changed and our hints are no longer working correctly is to set up an alert on a sudden spike in NULLs in hinted columns. In Databricks, this can be done with Delta Live Tables expectations, a lightweight data quality check scheduled as a separate job alongside our pipeline, or a Databricks SQL dashboard with an alert configured directly on the null count metric.
Hidden traps and limitations
Schema hints are straightforward to work with until they are not. Here is what tends to catch people off guard from my personal experience:
Hints that fail to convert produce NULLs, not errors. This is the most important behavior to remember. For example: if a column with a TIMESTAMP hint receives a string in a format Spark does not recognize, the pipeline will not throw an error, but the value will be silently replaced with NULL instead. From the engine’s perspective, everything ran successfully. From a data perspective, we just lost information. This is exactly why the monitoring practices covered in the previous section matter.
Case sensitivity in JSON column names. Even though Spark treats column names as case-insensitive by default, a JSON source can contain Transaction_ID and transaction_id as two entirely separate fields. Personally, I find this one to be the most subtle and easy to overlook trap when writing hints quickly. We have to make sure the name in our hint exactly matches the field name as it appears in the source file.
Different behavior depends on file format. In Parquet, files carry their own embedded schema. A hint does not cast the column to the specified type but instead instructs the Spark reader to read it as that type directly. In case of a type mismatch, the affected data lands in rescuedDataColumn rather than causing a pipeline failure. In CSV, schema hints are particularly important since CSV has no native type system. Without hints, every column is read as a string. In JSON, hints integrate most naturally, which is also the format used in most Databricks examples and documentation.
When NOT to use schema hints
Schema hints solve a real problem, but they are not the answer to every problem. Knowing when to skip them is just as important as knowing how to use them. Below are a few situations where a different approach will be more appropriate.
Hard validation is required. Schema hints will never reject a record. As we already know, a failed conversion produces a NULL silently, so if our pipeline needs to enforce data integrity by rejecting invalid records, schema hints are not the right tool. In that case, we should reach for Delta Lake constraints or explicit validation logic in our transformation layer.
Source schema is fully known and stable. If we are reading Parquet files, we should keep in mind that Parquet carries its own embedded schema. Auto Loader will pick it up automatically without any manual definition or hints, so we don’t need to use schema hints unless we want to override inference for a specific column. If we need a hard contract that fails when the producer changes the schema unexpectedly, then defining the full schema explicitly is an option.
Dealing with a highly dynamic schema. If the source regularly changes column types and names (which is an architectural problem itself), hints will require constant updates and most likely won’t keep up. Handling this kind of source reliably is a significantly more complex problem that needs a deeper architectural discussion. Approaches such as schema registry or data contracts are worth exploring in that particular case.
Summary
Schema hints are a lightweight tool that addresses one of Auto Loader’s most common weaknesses. While type inference does most of the heavy lifting for us, it may be unreliable for certain categories of data. Instead of choosing between a full manual schema and no control at all, hints offer a third path: minimal intervention, but precisely where it is needed.
They will not replace a proper data quality layer, and they are not meant to. But for the common case of a mostly inferable schema with a few columns that require guidance, they are hard to beat. Low effort, low maintenance, and when used with the monitoring practices covered earlier, reliable enough for production.
Key notes:
- Use hints selectively, only where inference gets it wrong
- A failed hint produces NULL, not an error. Consider monitoring
- Treat hints as code. Version them, comment them, review them
- Schema hints and schema evolution are not mutually exclusive and work well together
- Hints complement, not replace, our schema management strategy
***
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Visualization, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.







