(+48) 508 425 378
(+48) 508 425 378 office@bitpeak.pl
office@bitpeak.pl


Introduction to Case Study
AWS Glue is, amongst other AWS services, a great choice for a Big Data project. Alone or even with other services, like AWS Step Function and AWS EventBridge, it may help create a fully operational system for data analysis and reporting. The service provides ETL functionalities, facilitates integration with different data sources and allows a flexible approach to development.
In the following paragraphs I present a review of AWS Glue features and its functionalities based on a real example of integration with external databases and loading data form there to S3 buckets. Whole purpose of this exercise is to present technical side of the service using a practical case and building a simple solution step by step.
The Connection
In the reviewed case, the data source is a PostgreSQL database which is an external resource from AWS. It stores few tabular datasets that are supposed to be moved to Amazon S3. Someone could create a connection to scan this database directly In a form of a script, but here we can use AWS Glue Connections. It allows to create a static connection to databases which stores connection’s definition, the chosen user and its password. It delivers a possibility to connect external databases, Amazon RDS, Amazon Redshift, MongoDB and others.
Crawlers
Based on the established connection in AWS Glue, it is possible to scan databases to know what tables are available there. Developers can use AWS Glue Crawlers which may analyse whole databases model for a chosen database schema to create an internal representation of tables. A Crawler can be run manually or based on a schedule to scan one or more data sources. A successful scan of Crawler creates metadata in Data Catalog for Databases and Tables.
Databases and Tables
Databases in AWS Glue serve a purpose of containers for inferred Tables. Tables are just metadata and they reference actual data in an external source, i.e., their data are not saved in Amazon storage. In a situation where inferred Tables are created with Crawler scanning internal Amazon resources, those Tables would also act only as references. This means that deleting Tables in AWS Glue would only lead to deletion of metadata in Data Catalog, but not to deletion of physical resources on external databases or S3. What developers must also remember is that Tables from external resources are not available for ad-hoc queries using Amazon Athena, even though scanned Databases exists in Amazon Athena.
The Jobs
AWS Glue lets developers create Spark or simple Python jobs, where jobs’ settings can be modified to select type of workers, number of workers, timeouts, concurrency, additional libraries, job parameters and so on. Developers may create a job by writing and passing scripts using Amazon platform or using recent feature in AWS Glue Studio to create jobs with a visual designer.
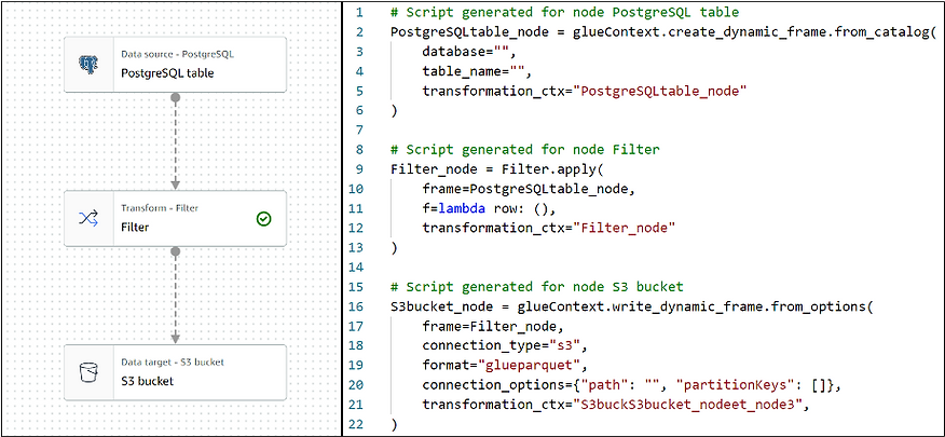
Picture presents a Glue Studio job in a visual form (left) and its representation in code (right).
Continuing with the case study, in the above picture there is a visually created job that would import data from PostgreSQL databases into S3 bucket. In this simple example, there are only three operations used (left side of the picture): Data source, Transform and Data target. Those operations and additional other built-in transformations simplify the process of creating Glue jobs. First operation directly creates a data frame from an external table by simply indicating Database and Table created in the previous steps. Then, by “filter” transformation, only specific data are saved into S3 bucket with the last operation.
All those three steps can be done manually just by the means of passing parameters in the visual designer. Moreover, visual transformations will generate a ready to run script (right side of the picture). This script can be modified, but that irreversibly switches off a possibility of further modification using the visual designer. This limitation only allows creation of simplest jobs or a start-up of bigger jobs.
The above steps show the features of AWS Glue. Some of them could be omitted, if one would like to create his/her own way of connecting to a different data source using credentials stored in AWS Secrets Manager instead of creating Connection in AWS Glue. Additionally, there are a couple more useful functions of AWS Glue that were omitted in this article, like Workflow, or Triggers. Apart from the nice sides of AWS Glue, there are some disadvantages that need to be taken into consideration. Those will be mentioned in next article about AWS Glue.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.