
 +48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com


The client
Santander Bank Polska, one of the biggest Polish banks with 10,000 employees and a part of a global group with 166 million customers, € 1,020 bn customer loans, € 1,800 bn total assets and € 1,184 bn customer deposits + mutual funds.
The client’s goal is to be the best open financial services platform, by responsible action and earning the meaningful trust of all stakeholders – people, customers, shareholders, and communities.
The challenge
Our client needed a modern data analytics platform which could unlock the potential of the enterprise’s data through new analytical processes and AI/ML solutions. The existing infrastructure made the implementation of new projects resource-heavy, particularly those involving real-time data processing. BitPeak’s goal was to modernize and update the technological infrastructure and enable bank to scale and develop their processing capabilities.
- Modernization of existing infrastructure: To enable the implementation of new, innovative projects, especially those requiring streaming data processing capabilities, implementation of new technological solutions such as CDL or dynamic filtering was necessary.
- Challenging deployment: Due to stringent internal and external regulations, need for regulatory approval from Polish Financial Oversight Body (KNF) and monolithic codebase, the deployment of new solutions required significant time and resources.
- Technological competition on the market: The client faced risk of falling behind technologically compared to competitors in the banking sector, that could leverage more advanced analytics and data processing capabilities.
The solution
A secure, scalable and easily developed analytics platform capable of storing, processing and feeding data to visualization solutions such as Power BI.
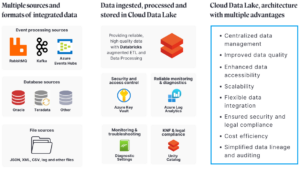
Qualitative Changes in Data Flow
The migration of the data platform to the cloud and the use of Azure components brought significant improvements in the organization’s data flow.
The Azure cloud platform provided the ability to scale resources up or down based on demand, ensuring efficient processing of large data volumes without compromising performance.
With Azure Databricks, the organization could implement real-time data processing pipelines, enabling faster decision-making based on available data.
Key Vault and Databricks’ Unity Catalog ensured data handling met GDPR and KNF requirements, enhancing data privacy and security.
GitHub Actions for CI/CD processes facilitated automated deployments, reducing manual intervention and the risk of errors.
Terraform allowed for the creation and management of infrastructure through code, enabling repeatable and consistent provisioning of resources and ensuring that the infrastructure setup is version-controlled and auditable.
Additionally, the CDL platform implements the Lakehouse concept, which combines the best features of data lakes and data warehouses. The structure is based on Delta Lake and utilizes Apache Spark for streaming data processing.
To manage data processing, we used Kappa architecture, which focuses on handling real-time and batch processing using a unified streaming architecture.
The result? Clean, reliable, standardized, high-quality data!
Technological Advancements
During the implementation, we provided our client with additional advanced functionalities through tailored, modern technological solutions:
- Configuration-Driven Framework: The framework powered by configuration files automated data ingestion, processing, and transformation, enhancing operational efficiency. It ensured integration with various source systems such as Kafka, RabbitMQ, Teradata, and more.
- Separate Configuration Repository: Configuration for the framework was placed in a separate repository, allowing for quick deployment of configuration changes to the environment.
- Dynamic Filtering and Tagging: Implementing dynamic data filtering based on column tags improved data management, making it easier to retrieve and analyze relevant data.
- Advanced Analytics and AI/ML Integration: The platform’s ability to support advanced analytics and AI/ML models unlocked new insights and business opportunities, driving innovation within the organization.
- Seamless Migration and Integration: The migration of existing BigData processes from the on-premises environment to the new platform was smooth, with minimal disruption to ongoing operations. The integration with existing ETL orchestration tools ensured continuity and consistency in data processing workflows.
- Monitoring and Alerting System: A cohesive system was established to monitor the platform and alert critical events, ensuring better system performance and reliability based on Azure Log Analytics.
To reach our goal, we used the following tech stack:
- Databricks Jobs and DLT: ETL processes
- Databricks Unity Catalog: Data Management
- Microsoft Azure: Cloud Platform
- Azure Data Lake Storage (ADLS): Data Storage
- Azure Log Analytics: Log Processing
- pySpark, Spark SQL: Data Transformation
- Azure DevOps: CI/CD

Benefits:
Strategy
Code structure optimization drastically reduced the time required to deploy new functionalities, from 2 months to just 2 weeks. Additionally, advanced analytics and integration with additional analytic tools empower our client to quickly react to dynamically changing business conditions. Business users were able to track and identify trends, patterns in client behavior and potential fraudulent activities. All of this resulted in quick and efficient tools for predictive analytics and processing data in real time empowering our clients to fulfill their digital transformation strategy.
Management
Our product allows for controlling huge volumes of data on multiple levels of organization, ensuring security and reliability. Additionally, Azure’s Cloud Data Lake capabilities empower data owners to efficiently manage the information, scale the data-based processes and prepare configurations. At the same time introduced cloud computing enabled flexible resource management, allowing bank to pay only for what they actually use – ensuring lower costs and greater control over the data.
Legal compliance
Our solution passed all internal regulations and allowed for easier legal compliance due to emphasis on structure clarity, strict access control, data safety and information security. Due to our expertise we were also able to design solution quickly accepted by KNF (Financial Control Commission) – the highest financial oversight body in Poland, with power to accept or reject any cloud computing solution in financial institutions.







