(+48) 508 425 378
(+48) 508 425 378 office@bitpeak.pl
office@bitpeak.pl


In a predictive machine learning project, feature engineering is one of the most crucial steps in obtaining a good model. Its purpose is to transform data and extract from it information that a machine learning model would struggle to identify on its own. In this step, domain expertise meets with knowledge of ML algorithms, enabling the algorithms to detect patterns and make accurate predictions effectively. Well-engineered features almost always make the difference between a poor and a highly performant model.
However, during the creation of a complex feature engineering pipeline, many mistakes can be made. In my opinion, the most crucial one is data leakage. It poses a serious risk as it can be introduced quite easily when building complex features, especially in time-dependent datasets. When this problem occurs, test results are overly optimistic, and in some cases, it can even render the model useless in a production environment. Data leakage often arises in the early stages of a project, when the complexity of the dataset is underestimated. When it happens, data scientists must waste valuable time fixing it. In this article, we will share our knowledge and experience on data leakage and provide you with some best practices and tips on how to prevent it.
Case Study: Flight Delay Prediction Project
In one of our recent projects, we had the opportunity to build a machine learning model for predicting flight delays. The objective was to create a model and evaluate its performance across different time horizons (24 hours to 15 minutes) leading up to an aircraft’s scheduled departure. Air traffic is inherently time-dependent: delays often propagate, and each flight can be influenced by the previous one. To capture this dynamics, we worked with multiple datasets that had complex relationships and varying time availability of features, and engineered a range of sophisticated features. Throughout the project, we faced a full spectrum of data leakage risks along the way. However, by following best practices and fully understanding the problem, we successfully delivered a high-performing, production-ready model with no leakage. All examples in the following sections will be based on this case study.
Time-dependent data
Characteristics of time-dependent data
Time-dependent data, such as time series, transaction logs, or streaming data, exhibit unique characteristics that set them apart from static data. In these dynamic datasets, the sequence and timing of observations are critical, as future values typically depend on past events. Unlike static datasets, where records can be treated independently, temporal data introduces inherent correlations and dependencies, requiring careful consideration during data processing and modeling.
Data leakage in time-dependent contexts
Contrary to common belief, leakage doesn’t only occur when future data is used. Any feature that relies on information unavailable at the exact moment when prediction is made can introduce leakage. For example, aggregating values over a time window that extends beyond the prediction timestamp can unintentionally provide the model with knowledge it wouldn’t have access to in a real-world scenario. Even within a single record, some columns may contain data collected or updated after the prediction point, while others are valid. These subtle and easy-to-overlook details can cause data leakage, with all its consequences.
Types of data leakage in time-aware feature engineering
As discussed earlier, time-dependent data introduces unique risks and therefore requires special treatment. Before we move into specific challenges and best practices, it’s essential to understand how leakage typically happens in time-aware feature engineering.
Below are the most common types of leakage dangers that we encountered in our Flight Delay Prediction Project. These examples are drawn from the aviation industry, but the underlying mistakes can apply to any project working with evolving, real-time data. Each of these can silently inflate model performance during development, while leading to failure in production.
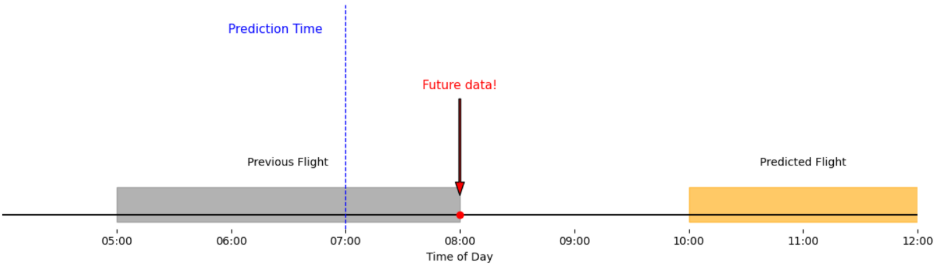
Future data leakage
This is the most obvious and well-known form of leakage. It occurs when features include information from the future, meaning after the point in time when a prediction is supposed to be made. Such leakage can result from using target variables, finalized outcomes, or future aggregations during feature engineering.
Example: Predicting a delay 3 hours before departure using the actual arrival delay of the aircraft’s previous flight, even though that flight hasn’t arrived yet.
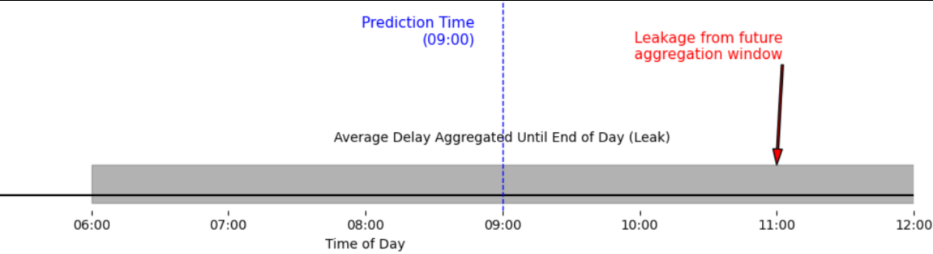
Leaked aggregations
Even when working with historical data, aggregations such as rolling averages, standard deviations, or event counts can introduce leakage if not carefully time-shifted. If a rolling window extends past the prediction timestamp, the resulting features will contain data that would not be available at inference time.
Example: Calculating the average delay at an airport using all flights up to the end of the current day, rather than only those before the prediction time.
Availability assumption
This type of leakage happens when features are technically historical, but their timestamp of availability does not match the moment of prediction. For example, an external data source may be updated with delays several minutes after an event occurs, but the feature engineering process assumes immediate availability.
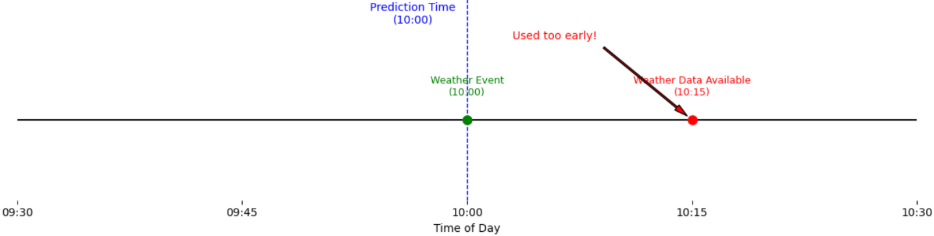
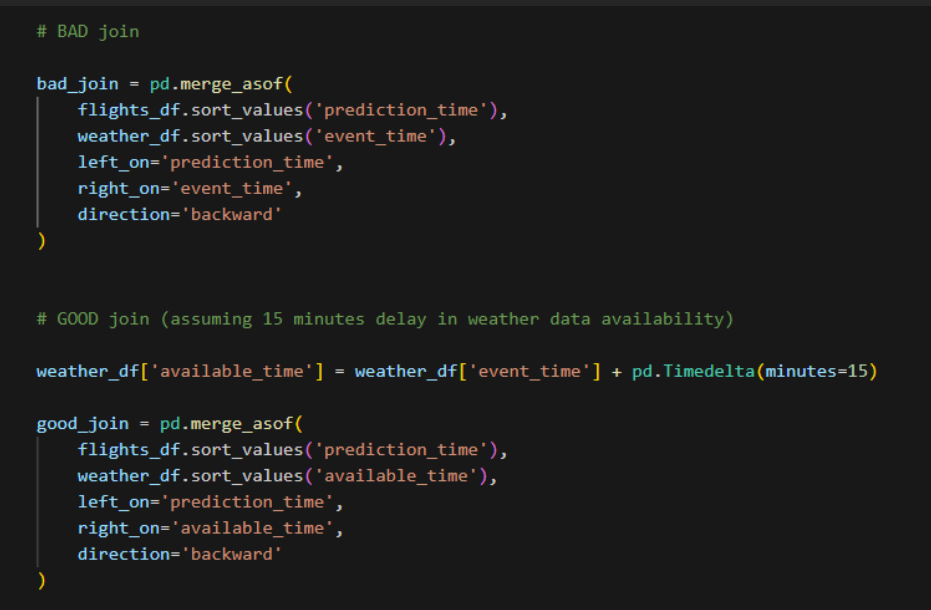
Example: Using weather reports issued at 10:00 AM for a prediction made at 10:00 AM, even though the report was only published at 10:15 AM.
Inconsistent granularity
Combining data sources with different update frequencies or time resolutions without aligning them properly can introduce implicit leakage. A high-frequency dataset might „peek” into future trends if joined too naively with a low-frequency counterpart.
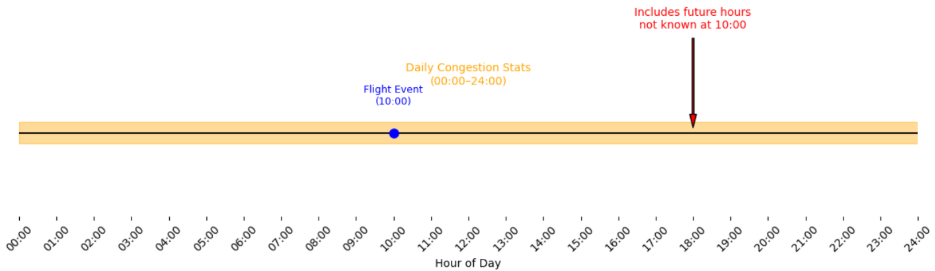
Example: Merging hourly flight events with daily airport congestion statistics, but allowing the daily data to reflect the full day, including future hours not yet known at prediction time.
Recognizing these leakage patterns is essential for building reliable models. As you can see, in time-aware feature engineering, even small missteps in how data is aggregated, joined, or timestamped can invalidate the model’s real-world performance.
Common challenges in time-aware feature engineering
Understanding each column availability
From our experience, one of the most common challenges is identifying and understanding the time availability of each column in the dataset. This information is often not explicitly stated and requires close collaboration with the business team and domain experts to use each feature correctly. It is as difficult as it is important, because without a clear understanding, there is a high risk of causing data leakage and producing misleading model results.
Integration of diverse data sources
Working with data from different sources presents significant challenges, especially when those sources update at different times, have different levels of detail, or include delays. If datasets aren’t synced properly – for example, combining daily weather data with hourly transactions without careful alignment – it can lead to mistakes, wrong conclusions, or even data leakage.
Handling future-dependent target labels
In many time-based projects, the target label depends on what happens in the future. For example, defining a flight delay, a customer churn, or an issue often needs information that isn’t available at the moment of prediction. If the label is created using data that comes later, like using the actual flight arrival time instead of what was known at departure, it can lead to hidden data leakage. To avoid this, targets must be created using only the information available at the right moment. Doing so requires clear definitions, handling timestamps carefully, and often building custom logic to reflect how the model will work in the real world.
Choosing appropriate time windows
Picking the right time window for feature aggregation is another challenge. If the window is too short, the model might miss important trends. If it’s too long, it risks incorporating irrelevant data and diluting the signal. Both scenarios can reduce model accuracy and undermine the reliability of the results. In our project, we tested several time windows for each aggregation and chose the ones that gave the best results. The best approach here is through experimentation, and we highly recommend it.
General best practices in time-aware feature engineering
Thorough data understanding before engineering features
Before starting exploratory data analysis or feature engineering, it is crucial to invest time in deeply understanding the structure, origin, and timing characteristics of your data. In our Flight Delay Prediction Project, we spent a significant amount of time, before even starting modeling, collaborating with domain experts. This early investment paid off, resulting in a smooth modeling process without unnecessary setbacks or corrections. We precisely mapped the availability of each data point over time, documented the temporal relationships between features, and developed a deep understanding of what each feature represented.
Rigorous temporal validation
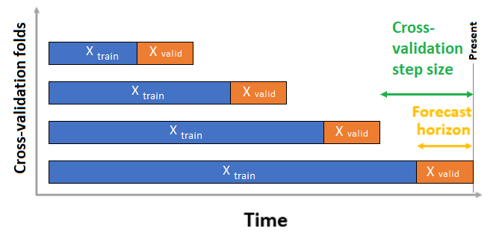
Proper validation of predictive models using temporal data requires strict separation of training and testing datasets based on time. Unlike random splits common in static datasets, temporal validation ensures that models are evaluated only on data that comes strictly after the training period. In our Flight Delay Prediction Project, we followed this principle carefully. For every evaluation step, we made sure that the model was trained only on data available up to a certain point in time and tested exclusively on future data. This approach helped us replicate the actual production scenario, where predictions must be made without knowledge of future events. By maintaining this chronological order during validation, we avoided any risk of data leakage and ensured that the performance metrics truly reflected how the model would behave in a real-time environment.
Source: Microsoft Learn
Automation and scalability of the process
Automating feature engineering processes significantly increases the efficiency and reproducibility of workflows, especially when working with complex, time-dependent data. For the flight delay prediction task, we built a dedicated pipeline that allowed us to generate features in a consistent and repeatable way, without risking data leakage. This automation helped us enforce strict temporal rules and ensured that all features were based only on information available at the time of prediction. With the pipeline in place, we could quickly test different feature sets and iterate on ideas without worrying about introducing subtle mistakes.
Modularity and interpretability
Taking a modular approach to feature engineering made a big difference for us when working with time-based data. We built the pipeline as a set of small, independent pieces, which made it much easier to manage, scale, and understand. It also helped us move faster – trying out new features or tweaking existing ones was simple and didn’t break the whole setup. When we identified potential data leakage, we were able to resolve it by modifying a single function, rather than revisiting the entire pipeline. This made the whole process quicker, cleaner, and much easier to maintain.
Summary
Time-aware feature engineering plays a crucial role in any project involving time-dependent data. One of the most important lessons we’ve learned from our experience is this: understand your features and when each piece of information becomes available. Skipping this step can easily lead to data leakage, misleading performance metrics, and poor results once the model is deployed.
To avoid these issues, we focused on a few essential practices: respecting temporal boundaries, using proper time-based validation, keeping our feature engineering pipeline modular, and clearly tracking data availability at the column level. This approach helped us catch potential problems early and make changes quickly without disrupting the entire process.
By implementing these practices, your team can avoid the costly pitfalls of data leakage and build more reliable, production-ready models.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.