
 +48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com



In the first part of this series, I outlined how to approach the decision to migrate to Databricks. The goal was to understand when migration is justified and what conditions need to be in place before starting. In this article, the focus shifts to what comes next. Once the decision is made, the real work begins with defining the High Level Design and aligning on the key constraints that will shape the target platform.
Migration to a new data platform is rarely a matter of changing a tool. It usually means intervening across the entire ecosystem: integrations, batch and streaming ingestion and processing pipelines, reporting, ML models, access management, infrastructure, and cost governance.
The decision to migrate to Azure Databricks requires analysis and a clear plan, developed jointly across the organization. This typically involves Principal and Lead Data Architects, through Data Platform Managers, to leaders of Data Engineering and BI leads, as well as teams responsible for the cloud platform.
And the first technical step in migration planning is to analyse the current system and prepare a target High Level Design (HLD).
Analisys of existing solution
Below is a simplified example of a data processing solution that exposes common premises and anti-patterns of legacy data solutions:
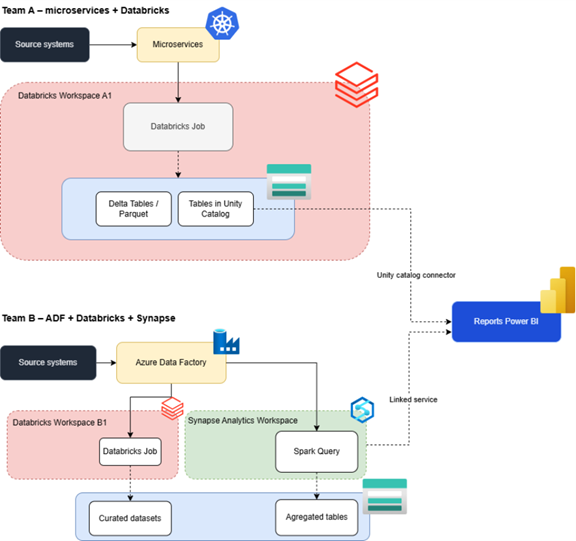
The diagram illustrates a fragmented data platform in which two teams have built parallel solutions. They appear similar on the surface but diverge in almost every dimension.
Data is processed along two separate paths – one centered on Databricks jobs, the other on ADF, Databricks and Spark in Synapse. ETL and ELT logic are spread across three different places, and competencies are duplicated.
Orchestration is split between a Databricks- and Kubernetes-oriented style and ADF-driven pipelines, which blocks a single standard for CI/CD, retries and alerting.
Data flows follow different routes and storage patterns: Delta and Unity Catalog on one side, ADLS and Synapse views on the other. As a result, lineage is incoherent and debugging data quality, especially where reports mix both worlds, becomes difficult.
There is no single analytical store or catalog: Delta tables sit partly in Unity Catalog and partly as files only, while curated and aggregated data lives in ADLS for Synapse. As a result, the same business concepts are modelled differently, and there is no clear source of truth.
Unity Catalog is used only in one part of the ecosystem, so governance and security based on UC never cover the full platform.
Reporting split: Power BI connects both to Databricks and UC and to Synapse materialized views, leading to two semantic layers, inconsistent KPIs and definitions, growing configuration, security and FinOps overhead.
Cost and workload visibility are scattered across Databricks, Synapse and ADF, so TCO by domain or use case is hard to establish, and cost control is difficult.
Security and permissions are managed in different ways. Unity Catalog, groups and BI connectors are used in one, while Synapse, ADLS and ADF are used in the other. This complicates permission management and audits.
Underlying this is a pattern of local optimization, each team improves its own stack because it seems faster, so the platform drifts further apart and unification into a single Databricks-based lakehouse becomes both more necessary and more expensive over time.
Preparing High Level Design – key technical and regulatory factors
Building the architecture on a shared understanding of constraints and objectives reduces the risk of later rework and enables a coherent, compliant, and maintainable platform. Before you choose a specific target architecture, you need a set of boundary conditions that set direction and expectations. Without them, the project will keep changing course. This process should lead to development of High Level Design (HLD) that defines the the approach to key aspects, such as:
- Subscriptions and policies
- Workspace and data catalog structure
- IAM principles
- Monitoring
- FinOps
- Software development lifecycle (SDLC) standards
Without a proper High-Level Design, migration turns into a stream of ad-hoc decisions made in code and on the platform – and thus into more technical debt.
Dependencies and order of decisions are shown in diagram:
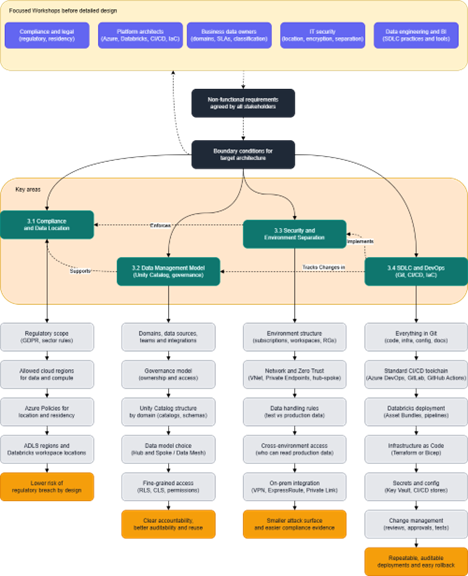
Diagram shows typical areas that must be consciously defined.
Compliance requirements and data location
Compliance requirements are often non-negotiable and take precedence over cost or performance optimization. Incorrect data locations can lead to fines, loss of certifications, or contract termination. Changing data location after implementation is costly and time-consuming.
Questions to answer
Usually, there are top-down regulations that must be met when working with data in the organization (e.g., GDPR). Due to sectoral or internal regulations and customer contracts, organizations follow policies on data location. Sometimes the consequences of breaching those might be severe.
To address the topics mentioned above, it is necessary to determine location for data residency and running compute.
Impact on architecture
Defining Azure Policies for location enforcement implies region for creation resources like Databricks Workspaces, Compute and Storage( ADLS). Also, the number and location of Databricks Workspaces should be chosen based on organizationalpolicies and governance constraint.
This approach lowers the risk of regulatory breach by design.
Data management model
Without a clear data management model, Unity Catalog quickly becomes another “store of everything” where no one can distinguish truth from duplicate. Lack of domain owners leads to situations where no one is accountable for data quality or access decisions. Inconsistent catalogs make auditing, data reuse, and onboarding difficult.
Questions to answer
First, it is essential to recognize and define current and desired data management model. The goal is to create Unity Catalog adoption scenario in Databricks. It requires identification of: data residency, business domains, data sources, approach for data processing stages (medallion architecture in Databricks) and engaged teams . Also, data governance model needs to be defined – structure of ownership and access management procedures. This includes listing all current integrations with external dashboards, platforms, and tools that are consuming data from our platform. Based on this information, we can define criteria for catalogs and schemas in newly created Unity Catalog.
Impact on architecture
Definition of data model and data governance affects auditability, data reuse and ease of onboarding. It is required to organize catalogs and schemas by domain.
Then it is important to choose an appropriate data model, for example we can choose Hub & Spoke or Data Mesh, depending on business needs. Each of them brings different pros and cons and are suitable for different needs.
In terms of access policies, we need to define fine-grained permissions in Unity Catalog, Row-Level Security (RLS), and Column-Level Security (CLS).
Correct definition of data model and governance leads to clear accountability for data because each domain has an owner responsible for quality and access.A clear catalog and schema structure makes it easier to audit and maintain a platform, discover data, and improves onboarding of new domains and contributors.
Link to compliance
Without clear data ownership and catalog structure, it is difficult to identify sensitive data (GDPR/PII) and manage it in line with requirements. Due to constantly emerging new regulations regarding data privacy policies, like for example “the right to be forgotten”, some systems need to be capable of addressing such requirements. Also, while running audits, you need a clear picture of who has access to what data and why.
Security and environment separation
Without a clear model for security and environment separation, it becomes easy to run production processes in test by mistake or to expose sensitive systems unnecessarily. At the same time, excessive isolation makes the platform harder to maintain and can slow down collaboration between teams. The aim is to strike a conscious balance between strong protection of critical assets and a level of shared infrastructure that keeps operations manageable.
Questions to answer
First, it is necessary to decide how strong environment separation should be and how they should be organized. This includes choosing the workspace separation strategy: whether each environment has its own workspace or whether a single workspace is used by multiple environments with separate catalogs and accesses managed on multiple levels like: user groups and Entra IDs through Unity Catalog and network design..
Network design including communication between environments, Zero Trust approach to access of assets like Databricks workspaces or Azure resources as well as deciding how remote users can connect to the platform and integration with on-premise systems.
Data handling rules are required including policies for sensitive or personal data among environments.
Access management between environments as well as for the assets within them must be defined. Governance and access model is required upfront to maintain manageable and secure platform.
Impact on architecture
The decisions around security and environment separation directly shape both the network and subscription topology and the operational complexity of the platform. Network architecture, including hub-and-spoke patterns, Azure Policiy definitions, Private Endpoints and VNet injection for Databricks clusters, must reflect the chosen isolation level and Zero Trust requirements. Subscription structure among workspaces and resource groups, defines how costs, policies and permissions are managed.
Correctly defined network policies architecture and environment separation provide stronger security with a smaller attack surface and make it easier to demonstrate compliance in audits. Clear separation between environments reduces the risk of misrouted processes and accidental use of the wrong environment. At the same time, a deliberate trade-off between isolation and shared infrastructure allows teams to work efficiently while keeping the platform maintainable.
Link to compliance and data model
Regulatory requirements may mandate strong The chosen data management and governance model influences how access between environments is organized, how sensitive data is protected and how audit trails are maintained. Addressing these aspects enables platform to consistently meet regulatory, security and business expectations.
SDLC and DevOps
Without a robust SDLC and DevOps approach, every change to the platform becomes a manual operation in the user interface, increasing the risk of errors and making rollback slow and unreliable. Without version control, changes to code and configuration cannot be tracked, reproduced, or reverted. Inconsistent CI/CD practices across teams slow down delivery and accumulate technical debt.
Questions to answer
The starting point is to define whether everything is stored and managed in Git: code that runs in Databricks (including job and pipeline definitions), infrastructure definitions (e.g. Terraform), and documentation such as READMEs and runbooks, so that changes are versioned, reviewed and traceable.
It is also important to define how secrets and environment-specific configuration are managed and stored having in mind security and accessibility.
A standard CI/CD toolchain and approach must be selected and the shape of Databricks pipelines must be defined: whether to use Databricks Asset Bundles or more traditional deployment methods. Deployment flows across environments need to be clarified, for example whether deployments to dev are automatic while test and production require approvals, and how automated unit and integration tests fit into the pipeline to validate changes before release.
Impact on architecture
The SDLC and DevOps model ensures repeatability and reliability of deployments. Repository structure influences cross-teams collaboration.
The choice of CI/CD tools and patterns defines how Databricks artefacts are built, tested, and promoted between environments. Using Databricks Asset Bundles can standardize how jobs, pipelines and configuration are defined and deployed, and Infrastructure as Code, for example Terraform, aligns Azure and Databricks infrastructure with the desired architecture, including Workspaces, Unity Catalog, networking and security settings.
Clear processes and procedures for change management, code review and deployment documentation are required so that changes are visible, approved and auditable.
A mature SDLC and DevOps model leads to repeatable deployments where all environments can be recreated via pipelines. Rollback becomes straightforward, collaboration gets seamless and technical debt is reduced because every change is documented and its history is visible.
Link to security and data model
SDLC and DevOps practices underpin both security and data management.
Version control and code review help identify security issues before they reach production, and automated deployment pipelines reduce the risk of configuration errors that could expose data or services.
Infrastructure as Code ensures alignment with security and compliance standards, for example through Azure Policy and Terraform repeatable templates. The data management model also benefits from having all changes to model, permissions and governance processes tracked in Git, making the evolution of the platform transparent and auditable.
Summary
If areas defined above are not clarified, any attempt to define a high-level design will result in a document that interpreted differently between responsible teams.
Before moving into detailed architecture design, it is therefore essential to hold focused workshops with key stakeholders:
- compliance and legal teams to capture regulatory and data residency requirements
- business data owners to clarify requirements, classify data, define domain models and SLAs
- IT security to specify technical requirements such as location, encryption and environment separation;
- platform architects to shape the solution framework around Azure and Databricks capabilities, CI/CD tools and Infrastructure as Code;
- and data engineering and BI leaders to define SDLC practices, tools and processes.
All outcomes from these discussions should be documented as non-functional requirements and agreed with all stakeholders before detailed design begins.
***
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Visualization, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.







