
 +48 453 250 842
+48 453 250 842 office@bitpeak.com
office@bitpeak.com

Introduction
Data Factory is a powerful tool used in Data Engineers’ daily work in Azure cloud service. The code-free and user-friendly interface helps to clearly design data processes and improve Developer experience. It has many functionalities and features, which are constantly developed and enhanced by Microsoft.
The tool is mainly used to create, manage and monitor ETL (Extract-Transform-Load) pipelines which are the essence of the data engineering world. Therefore, I can confidently say that Data Factory has become the most integral tool in this field in Azure. But have you ever thought about the cost, that the service generates each time it is run? Have you ever done a deep dive into consumption run details, in order to investigate and explain the final price you have to pay each month for the tool?
Whether you have hundreds of long-running daily pipelines or use Data Factory for 10 minutes, once a week in your organization, it generates costs. Therefore, it is a good practice to know how to deal with it and create well-designed, cost-effective pipelines. In this article, you will find out how the small details can double your monthly invoice for Data Factory service. Azure is a pay-as-you-go service, which means that you pay only for what you actually used. However, the pricing details might overwhelm at first sight, and I hope the article will help you understand it more deeply. When you open official website (here or here) you can see that costs are divided into two parts: Data Pipeline and SQL Server Integration Services. In this article I will discuss only the Data Pipeline part, so let’s analyze it together.
Data Pipeline
First of all, it is important to realize that you are not only charged for executing pipelines, but the cost for Data Pipeline is calculated based on the following factors:
- Pipeline orchestration and execution
- Data flow execution and debugging
- Number of Data Factory operations (e.g. pipeline monitoring)
Pipeline orchestration
You are charged for data pipeline orchestration (activity run and activity execution) by integration runtime hours. Azure offers three different integration runtimes which provide the computing resources to execute the activities in pipelines. The below table presents the cost for each integration runtime.
| Type | Azure Integration Runtime Price | Azure Managed VNET Integration Runtime Price | Self-Hosted Integration Runtime Price |
| Orchestration | 1$ per 1 000 runs | 1$ per 1 000 runs | 1.5$ per 1 000 runs |
*the presented prices are for West Europe region in March 2022, source.
Orchestration refers to activity runs, trigger executions and debug runs. If you run 1000 activities using Azure Integration Runtime you are charged $1. The price seems to be low, but if you have a process that runs a lot of activities in loops many times a day, you could be surprised how much it could cost at the end of the month.
If you want to study existing pipelines in Data Factory, I recommend you to check the value in Data Factory/Monitoring/Metrics section by displaying charts Succeeded activity runs and Failed activity runs. The sum of these values is a total number of activity runs. The below picture presents how you can check the statistics for Data Factory instance for last 24 hours.
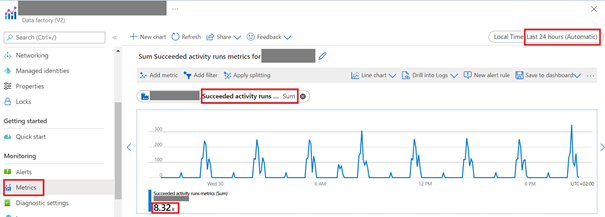
As you can see in the above example, the pipelines are executed every 3 hours and the total number succeeded activity runs is 8320. How much does it cost? Let’s calculate:
Daily price: 8320/1000 * $1 = $8.32
Monthly price: 8320/1000 * $1 * 30 days = $249.6
Pipeline executions
Every pipeline execution generates cost. Pipeline activity is defined as an activity which is executed on integration runtime. The below table presents the pricing of execution Pipeline Activity and External Pipeline Activity. As demonstrated in the below table, the price is calculated based on the time of execution and the type of integration runtime.
| Type | Azure Integration Runtime Price | Azure Managed VNET Integration Runtime Price | Self-Hosted Integration Runtime Price |
| Pipeline Activity | $0.005/hour | $1/hour | $0.10/hour |
| External Pipeline Activity | $0.00025/hour | $1/hour | $0.0001/hour |
*the presented prices are for West Europe region in March 2022, source.
Depending on the type of activity that is executed in Data Factory, the price is different, as illustrated in Pipeline Activity and External Pipeline Activity sections in the table above. Pipeline Activities use computing configured and deployed by Data Factory, but External Pipeline Activities use computing configured and deployed externally to Data Factory. In order to show which activity belongs where, I prepared the below table.
| Pipeline Activities | External Pipeline Activities |
| Append Variable, Copy Data, Data Flow, Delete, Execute Pipeline, Execute SSIS Package, Filter, For Each, Get Metadata, If Condition, Lookup, Set Variable, Switch, Until, Validation, Wait, Web Hook | Web Activity, Stored Procedure, HD Insight Streaming, HD Insight Spark, HD Insight Pig, HD Insight MapReduce, HD Insight Hive, U-SQL (Data Lake Analytics), Databricks Python, Databricks Jar, Databricks Notebook, Custom (Azure Batch), Azure ML, Execute Pipeline, Azure ML Batch Execution, Azure ML Update Resource, Azure Function, Azure Data Explorer Command |
*source
Rounding up
While executing pipelines, you need you know that execution time for all activities is prorated by minutes and rounded up. Therefore, if the accurate execution time for your pipeline run is 20 seconds, you will be charged for 1 minute. You can notice that in the activity output details in the billingReference section. The below pictures present an example of executing Copy Data activity.

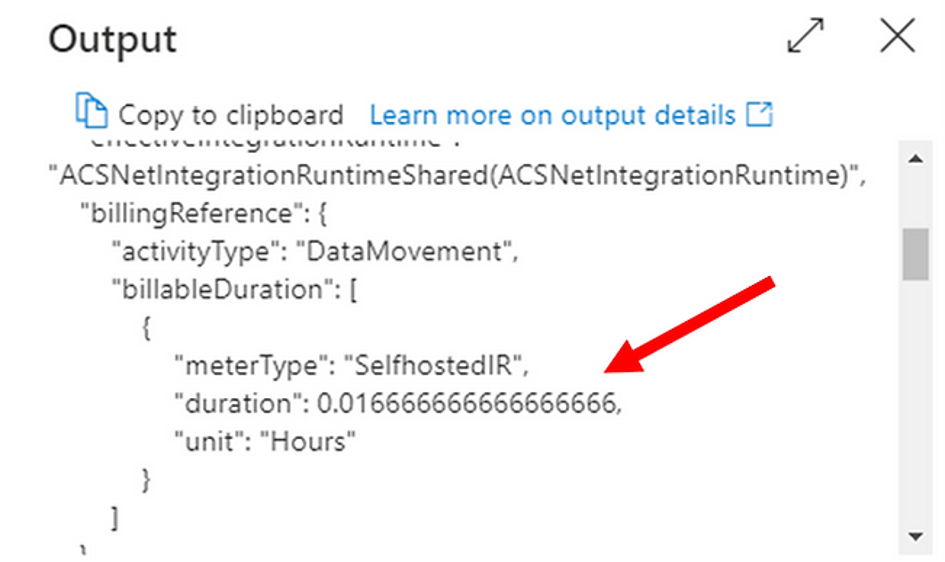
The section billingReference in output details of execution of the activity holds information like meterType, duration, unit. The pipeline was executed on self-hosted integration runtime and lasted 1/60 min = 0.016666666666666666 hour, although the time of execution was 20 seconds.
Inactive pipelines
It was really surprising for me, that Azure charges for each inactive pipeline which has no associated trigger or zero runs within one month. The fee for it is $0.80 per month for every pipeline, so it is crucial to delete unused pipelines from Data Factory especially when you deal with hundreds of pipelines. If you have 100 unused pipelines in your project, the monthly fee is $80 and the yearly cost is $960.
Copy Data Activity
Copy Data Activity is one of the options in Data Factory. You can use it to move the data from one place to another. It is important to know that in Settings you can change the default Auto value to 2. By doing so, you can decrease the data integration unit to a minimum, if you copy small tables. In general, the value of units can be in the range of 2-256 and Microsoft has recently implemented a new feature for Auto option. When you choose Auto, it means that Data Factory dynamically applies the optimal DIU setting based on your source-sink pair and data pattern.
The below table presents the cost of consumption of one DIU per hour for different types of integration runtime.
| Type | Azure Integration Runtime Price | Azure Managed VNET Integration Runtime Price | Self-Hosted Integration Runtime Price |
| Copy Data Activity | $0.25/DIU-hour | $0.25/DIU-hour | $0.10/hour |
*The presented prices are for West Europe region in March 2022, source.
Let’s estimate cost of a pipeline that has only Copy Data Activity.
Example:
If Copy Data Activity lasts 48 seconds, the copy duration time is rounded up to 1 minute, so the cost is equal to:
1 minute * 4 DIUs * $0.25 = 0.0167 hours * 4DIUs * $0.25 = $0.0167
As you can see the price $0.0167 seems to be low, but let’s consider it more deeply. If you execute the pipeline for 100 tables every day, the monthly cost is equal to:
$0.0167 * 100 tables *30 days = $50.1
If you execute the pipeline for 100 tables every single hour, the monthly cost is equal to:
$0.0167 * 100 tables * 30 days * 24 hours = $1,202.4
The most crucial part of creating the pipeline solution is to keep in mind that even if you handle small tables, but do it very often, it could dramatically increase the total cost of the execution. If it is feasible, I recommend preparing the data upfront and using one large file instead. You can just code a simple Python script.
Bandwidth
The next factor that could be relevant in regard to pricing is Bandwidth. If you want to transfer the data between Azure data centers or move in or out the data of Azure data centers you can be additionally charged. Generally, moving the data within the same region and inbound data transfer is free, but the situation could be different in other cases. The price depends on the region, internet Egress and differs for Intra-continental or Inter-continental data transfer.
For example, if you transfer 1000 GB data between regions within Europe, the price is $20, but in South America it is $160. When it is necessary to move 1000 GB from Europe to other continents the price is $50, but from Asia to other continents it’s $80. Therefore, think twice before you decide where to locate your data and how often you will have to transfer it. As you notice, there are many factors contributing to the bandwidth price. You can find the whole price list in Azure documentation.
Data Flow

Data Flow is a powerful tool in ETL process in Data Factory. You can not only copy the data from one place to another but also perform many transformations, as well as partitioning. Data Flows are executed as activities that use scale-out Apache Spark clusters. The minimum cluster size to run a Data Flow is 8 vCores. You are charged for cluster execution and debugging time per vCore-hour. The below table presents Data Flow cost by cluster type.
| Type | Price |
| General Purpose | $0.268 per vCore-hour |
| Memory Optimized | $0.345 per vCore-hour |
*the presented prices are for West Europe region in March 2022, source.
It is recommended to create your own Azure Integration Runtimes with a defined region, Compute Type, Core Counts and Time To Live feature. What is really interesting, is that you can dynamically adjust the Core Count and Compute Type properties by sizing the incoming source dataset data. You can do it simply by using activities such as Lookup and Get Metadata. It could be a useful solution when you cope with different dataset sizes of your data.
To sum up, in terms of Data Flows in general you are charged only for cluster execution and debugging time per vCore-hour, so it is significant to configure these parameters optimally. If you want to use one basic cluster (general purpose) for one hour and use a minimum number of Core Count, the total price of execution is equal to:
$0.268 * 8 vCores * 1 hour = $2,144
The monthly price is equal to:
$0.268 * 8 vCores * 30 days * 1hour = $64.32
There are four bottlenecks that depend on total execution time of Data Flow:
- Cluster start-up time
- Reading from source
- Transformation time
- Writing to sink
I want to focus on the first factor: cluster start-up time. It is a time period that is needed to spin up an Apache Spark cluster, which takes approximately 3-5 minutes. By default, every data flow spins up a new Spark cluster, based on the Azure Integration Runtime configuration (cluster size etc.). Therefore, if you execute 10 Data Flows in a loop each time, a new cluster is spun up, ultimately it can last 30-50 minutes just for start-up clusters.
In order to decrease cluster start-up time, you can enable Time To Live option. The feature keeps a cluster alive for a certain period of time after its execution completes. So, in our example each Data Flow will reuse the existing cluster – it starts only once, and it takes 3-5 minutes instead of 30-50 minutes. Let’s assume that the cluster start-up lasts 4 minutes.
| | Scenario 1 – Estimated time of executing 10 Data Flows without Time To Live | Scenario 2 – Estimated time of executing 10 Data Flows with Time To Live |
| Cluster start-up time | 40 min | 4 min (+ 10 min Time to Live) |
| Reading from source | 10 min | 10 min |
| Transformation time | 10 min | 10 min |
| Writing to sink | 10 min | 10 min |
The table above presents two scenarios of execution 10 Data Flows in one pipeline, but the second option has Time To Live feature that lasts 10 minutes.
Cost of executing the pipeline in scenario 1:
70 mins/60 * $0.268 * 8 vCores = $2.5
Cost of executing the pipeline in scenario 2:
44mins/60 * $0.268 * 8 vCores = $1.57
It easy to see that the price in scenario 1 is much higher than in scenario 2.
The most crucial part of using Time to Live option is the way of executing the pipelines. It is highly recommended to use Time To Live only when pipelines contain multiple sequential Data Flows. Only one job can run on a single cluster at a time. When one Data Flow finishes, the second one starts. If you execute Data Flows in a parallel way, then only one Data Flow will use the live cluster and others will spin up their own clusters.
Moreover, each of them will generate extra cost from Time To Live feature, because clusters will wait unused for a certain period of time when they finish. In consequence, the cost could be higher than without Time To Live feature. In addition, before implementing the solution make sure if Quick Re-use option is turned on in integration runtime configuration. It allows to reuse a live cluster for many Data Flows.
Data Factory Operations
The next actions that generate cost are the „read”, „write” and „monitoring” options. The below table presents the pricing.
| Type | Price |
| Read/Write | $0.50 per 50 000 modified/referenced entities |
| Monitoring | $0.25 per 50 000 run records retrieved |
the presented prices are for West Europe region in March 2022, source.
Read/write operations for Azure Data Factory entities include „create„, „read„, „update„, and „delete„. Entities include datasets, linked services, pipelines, integration runtime, and triggers. Monitoring operations include get and list for pipeline, activity, trigger, and debug runs. As you can see, every action in the data pipeline generates cost, but this factor is the least painful one when it comes to pricing, because 50 000 is really a huge number.
Monitor
I would like to present you one feature that could be helpful in finding bottlenecks in your existing solution in Data Factory. First of all, every executed pipeline is logged in Monitor section in Data Factory tool. Logs contain a data of every step of the ETL process, including pipeline run consumption details, but there they are stored for only 45 days in Monitor. Nevertheless, it is feasible to calculate an estimated price of Pipeline orchestration and Pipeline execution.
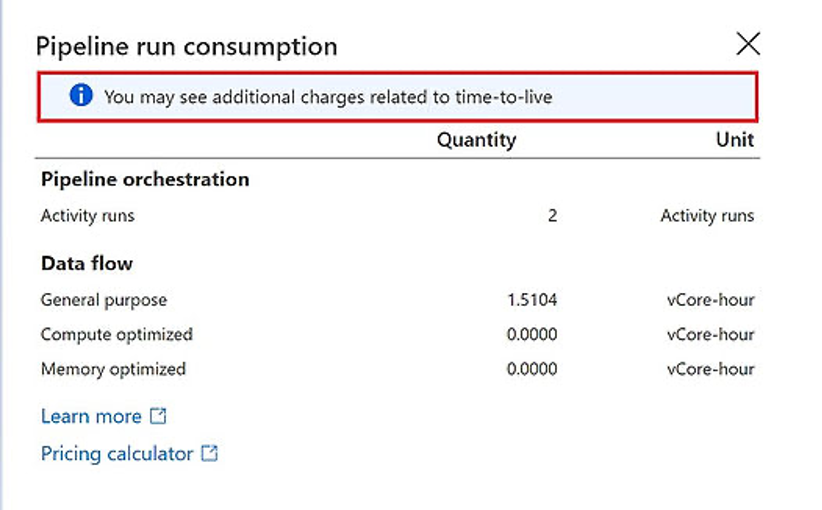
I found PowerShell code on Microsoft community website that generates aggregated data of pipelines run consumption within one resource group for defined time range. I strongly believe that the code can be useful for costs estimation of your existing pipelines. It is worth mentioning that this method has some limitations and for example it doesn’t contain information about consumption of Time To Live in Data Flows. In the picture below you can see this information in the red box.
I hope you found this article helpful in furthering your understanding of pricing details and the features that could be significant in your solutions. Microsoft is still improving Data Factory and while preparing this paper I needed to change two paragraphs due to the changes in Azure documentation. For example, from January 2022, you will no longer need to manually specify Quick Re-use in Data Flows when you create an integration runtime and that is great information. I found a funny quote that could describe Azure pricing in general: You don’t pay for Azure services; you only pay for things you forget to turn off – or in this case – “turn on”.
All content in this blog is created exclusively by technical experts specializing in Data Consulting, Data Insight, Data Engineering, and Data Science. Our aim is purely educational, providing valuable insights without marketing intent.







